OS Notes
本文最后更新于:2023年12月21日 凌晨
Intro to OS
计算机系统组成部分
- Hardware (CPU memory)
- Operating System
- Application programs
- Users
操作系统的作用
- Interface between user and hardware
- Control interaction between user and programs
- provide a controlled and efficient environment for the programs
- mange the whole resource of system
OS 的两个基本功能
- managing the hardware resources
- extending the hardware functionality
操作系统组成部分
- Process Manager
- Main-Memory Management
- File Management
- I/O System Management
- Secondary-Storage Management
- Networking
- Protection System
- Command-Interpreter System
操作系统的目标
- Efficient
- Interactive
- Robust
- Secure
- Scalable
- Portable
OS 组织结构
Monolithic structure
所有组件都在同一个内核中,他们之间可以直接交互,所有很高效。但是由于他的非结构化,导致不易理解,修改和维护。容易受到攻击。Susceptible to damage from errant or malicious code.
Layered Structure
组件被分层。 Designing the system as a number of modules gives the system structure and consistency. 允许调试,修改和再利用。进程的请求需要经过很多层,导致效率低下。
Microkernel Structure
- advantages: more security, stability, modularity, flexibility, portability, debuggability, and maintainability
- disadvantages: lower performance, increased complexity, and limited functionality
硬件
良好的硬件特性可以简化操作系统的设计。
双元操作模式:Kernel mode and user mode.
kernel mode: access to all the CPU instruction set also called monitor/system/privileged mode
user mode: access restricted to a subset of the instruction set
The mode is indicated by a status bit in a protected processor register.
保护指令阻止用户直接接触I/O,内存管理,执行CPU暂停。
System call
user希望调用特权命令。
陷阱指令跳转至内核处理陷阱。Using call parameters to determine which system routine to run.
Then hardware must implement caller’s parameters verification. Return to user-mode when call finished.
Exception(hardware-initiated interrupt)
异常是错误或特定情况自动触发的,不是故意的。
常见的异常:
- 内存超出用户访问空间
- overflow, underflow
- trace traps
- 非法使用特权指令
- paging fault
中断向量解决OS需求
Memory Protection
内存保护机制必须被保护
base and limit registers is simple scheme.
base ≤ address < base + limit
I/O Control
所有的I/O 指令都是特权指令。
- I/O start: handled by system calls
- I/O completion and I/O events: handled by interrupts
Interrupts are the basis for asynchronous I/O/
CPU Protection
Ensure that OS always maintains control. A user program might get stuck into an infinite loop and never return control to OS.
Timer: it generates an interrupt after a fixed or variable amount of execution time.
进程(Processes)
每个进程在自己的地址空间运行。两个不同进程中的相同地址被储存在不同地址的内存位置。
组成部分
- 程序代码(Text): 这是程序的实际可执行代码,也称为文本段。程序代码包含程序的指令集合,它定义了程序的逻辑和执行流程。这部分通常是只读的,因为它存储程序的源代码或二进制可执行文件,并且在程序的执行过程中不会被修改。
- 当前活动(Current Activity):这包括了程序的当前状态,包括程序计数器(Program Counter)和处理器寄存器(Processor Registers)。程序计数器是一个特殊的寄存器,它存储了当前执行的指令位置,用于跟踪程序的执行进度。处理器寄存器用于存储各种临时数据和控制信息,以支持程序的执行。
- 栈(Stack):栈是一个用于存储临时数据的数据结构。它通常包含函数调用的返回地址、局部变量、函数参数和其他临时数据。栈的管理是通过栈指针(Stack Pointer)来完成的,它指向栈的当前顶部。
- 数据段(Data Section):数据段用于存储全局变量和静态变量,这些变量在程序的整个执行期间都可以访问。数据段存储在进程的内存中,允许多个函数或代码模块之间共享数据。
- 堆(Heap):堆是用于存储在程序运行时动态分配的内存的一部分。堆的大小可以根据程序的需求动态增加或减小。通常,动态分配的内存用于存储数据结构、对象、字符串和其他需要在运行时动态创建和释放的数据。
进程状态(Process States)
进程状态(Process States)是指一个进程在其执行期间可能处于的不同状态
- 新建(New):当一个进程被创建时,它处于新建状态。在这个阶段,操作系统正在为进程分配资源,设置进程控制块(Process Control Block,PCB),并为进程初始化所需的数据结构。一旦所有准备工作完成,进程就会进入就绪状态等待执行。
- 运行(Running):运行状态表示进程正在执行其指令,使用CPU来执行任务。在任何给定的时间,通常只有一个进程能够处于运行状态,因为只有一个CPU核心可供进程执行。进程可以在运行状态中执行,直到它完成了其任务或者被操作系统暂停。
- 等待(Waiting):等待状态表明进程在等待某些事件或条件发生,以便继续执行。这些事件可以包括等待I/O操作完成、等待用户输入、等待信号或等待其他进程的通知。当进程处于等待状态时,它不占用CPU时间,并暂停执行,直到所需事件发生。
- 就绪(Ready):就绪状态表示进程已经准备好执行,但还没有被分配到CPU执行。通常,多个就绪进程等待CPU时间片,等待操作系统的调度器将它们分配给CPU。在多任务操作系统中,就绪状态的进程可能在队列中等待执行。
- 终止(Terminated):终止状态表明进程已经完成了它的任务并退出执行。在这个状态下,操作系统会清理并释放进程占用的资源,包括内存、文件句柄和其他资源。终止状态是进程的最终状态。
进程控制块(Process Control Block,PCB)
进程控制块(Process Control Block,PCB)是操作系统中的一个关键数据结构,用于存储与每个进程相关的信息。
- 进程状态(Process State):PCB 包含了一个字段,用于指示进程的状态,例如运行中(Running)、等待中(Waiting)、就绪(Ready)等。这有助于操作系统跟踪进程的当前状态,以确定是否可以分配CPU时间。
- 程序计数器(Program Counter,PC):PCB 中存储了程序计数器的值,它指示了进程下一条要执行的指令的位置。这允许操作系统在进程切换时恢复执行。
- CPU 寄存器:PCB 中通常包含了所有CPU寄存器的内容,这些寄存器包括通用寄存器、堆栈指针、帧指针等。这有助于保存进程的CPU状态,以便在切换进程时进行恢复。
- CPU 调度信息:PCB 包含了与 CPU 调度相关的信息,例如优先级、调度队列指针等。这些信息有助于操作系统选择下一个要执行的进程。
- 进程号(Process Number,PID):每个进程都有一个唯一的进程号,它在 PCB 中存储,用于标识特定的进程。PID 是操作系统用来管理和识别进程的重要标识。
- 内存管理信息:PCB 中可能包括了内存分配和管理相关的信息,包括进程的内存地址空间范围、页表、段表等。这有助于操作系统有效地管理进程的内存需求。
- 记账信息(Accounting Information):PCB 中可能包含有关进程的计算信息,如已使用的CPU时间、自启动以来的经过的时钟时间、时间限制等。
- I/O 状态信息:PCB 可能包括有关进程的I/O设备分配情况,以及已打开文件的列表等信息。
进程切换
进程切换是操作系统中的一个关键概念,它涉及保存和加载进程的状态以便在多任务系统中有效切换不同的进程。
- 进程状态保存和加载:当操作系统需要切换到不同的进程时,它会使用进程控制块(PCB)中存储的信息来保存当前正在执行进程的状态,包括程序计数器(PC)、寄存器内容等。然后,操作系统会加载下一个要执行的进程的状态,以继续执行。这个过程称为上下文切换(Context Switch)。
- 上下文切换的开销:上下文切换过程中,系统不会执行实际的工作,而是花费时间来保存和加载进程状态。这被称为上下文切换的开销,它是系统的一个负担。减少上下文切换的开销对于提高系统性能非常重要。
- 快速上下文切换:为了减小上下文切换的开销,操作系统需要设计快速的上下文切换机制。这通常涉及硬件和操作系统内核的优化,以确保尽可能快速地切换进程。快速上下文切换对于实现实时响应和高性能的系统至关重要。
- 切换频率的权衡:操作系统需要权衡进程切换的频率。如果切换得太频繁,会增加系统开销,降低性能。如果切换得太少,系统可能会变得不够交互式,不能满足用户需求。因此,操作系统需要根据不同的任务和需求来管理进程切换的频率。
进程创建(Process Creation):
进程的创建是指在计算机系统中启动新进程的过程。进程可以通过以下两种主要事件来创建:
- 系统引导(System Boot):当计算机系统启动时,通常会创建一些初始化进程,这些进程在系统启动时开始运行,为后续操作系统的正常运行提供基础。
- 执行进程创建系统调用(Process Creation System Call):在运行的进程内,可以通过执行进程创建系统调用(例如fork()在Unix/Linux系统中)来启动新的进程。这个新的进程是由调用进程创建并拥有自己的地址空间和资源。
进程终止(Process Termination):
进程的终止是指进程执行完毕或在某些条件下被终止的过程。进程可以以以下不同条件终止:
- 自愿终止(Voluntary Termination):这种终止是由进程自身决定的,通常发生在进程完成了其任务或者遇到错误时。例如,进程正常退出时(例如,通过调用exit()函数),或者在出现错误情况下终止时。
- 非自愿终止(Involuntary Termination):这种终止是由外部因素引起的,通常是由其他进程或系统错误引起的。例如,当一个进程发生严重错误(如访问非法内存)时,操作系统可以终止它。另一个例子是另一个进程(例如管理员或父进程)可以终止一个子进程。
- 从任何状态终止:自愿终止通常发生在运行状态下,但非自愿终止可以发生在任何进程状态下。一个进程可能在就绪、等待或运行状态下被非自愿终止。
子进程( Child Process )
进程可以创建新的子进程,形成一个层次结构的进程关系,通常称为进程树(Process Tree)。在这个关系中,创建新进程的进程被称为父进程,而新创建的进程被称为子进程。进程树的组织方式使得操作系统能够有效地管理和控制进程,同时保持层次结构的完整性。
- 父进程的影响:在某些操作系统中,当父进程终止时,它的所有子进程也会被终止。这是一种父子进程之间的强耦合关系。如果子进程需要继续运行,它可能需要被重新分配给另一个父进程。
- 孤儿进程(Orphan Process):当一个父进程终止,但它的子进程仍在运行时,这些子进程被称为孤儿进程。通常,孤儿进程会被重新分配给init进程或其他父进程,以确保它们能够继续运行。
- 僵尸进程(Zombie Process):当一个子进程终止,但其父进程没有正确地回收子进程的资源和状态信息时,子进程可能会成为僵尸进程。僵尸进程仍占用系统资源,但不再执行任何任务。它们应该被父进程正确回收,否则它们可能会在系统中积累。
- 回收僵尸进程(reaped) :操作系统和父进程需要正确地回收僵尸进程,以释放系统资源。如果父进程没有回收僵尸进程,通常是因为操作系统或父进程存在问题。
在Unix中的例子
- 创建子进程:在Unix操作系统中,可以使用
fork()系统调用来创建一个新的子进程。这个子进程是父进程的副本,几乎接收父进程的所有内容。 - 复制父进程的地址空间和 PCB:在实质上,
fork()系统调用会复制父进程的地址空间和进程控制块(PCB)。这包括父进程的代码、数据、堆、栈以及与父进程相关的进程信息。 - 子进程拥有新的PID:虽然子进程是父进程的副本,但它必须拥有自己独立的进程标识号(PID)。这是因为每个进程在系统中必须具有唯一的PID。
- PCB的复制:尽管子进程拥有新的PID,但它会继承父进程的PCB的副本。这包括了进程状态、程序计数器(PC)等信息。因此,子进程会从
fork()系统调用之后的位置开始执行,从父进程的状态中继承执行。 - 返回值:
fork()系统调用返回一个整数值。对于父进程,它会返回新创建子进程的PID。对于子进程,返回值为0,用于区分子进程和父进程。
进程通信(Interprocess Communication (IPC))
独立进程(Independent Processes):
独立进程是指那些在系统中既不会影响其他进程,也不会受其他进程影响的进程。这些进程之间不能共享系统状态或数据,它们在运行时彼此独立,没有交互。例如,位于不同非网络连接计算机上运行的进程就是独立进程的示例。
特点:
- 决定性行为 (Deterministic behavior):独立进程的行为是确定性的,只取决于其输入状态,因此结果是可复现的 (Reproducible)。
- 可以停止和重新启动:独立进程可以在不引起问题的情况下停止和重新启动。
合作进程(Cooperative Processes):
合作进程是那些在某种程度上共享信息或资源的进程,它们的执行可能会互相影响。这些进程可以共享数据、状态或资源,它们之间有某种形式的交互。例如,共享同一个文件系统的进程就是合作进程的示例。
特点:
- 非确定性行为(Nondeterministic):合作进程的行为通常是非确定性的,因为多种因素可能会影响结果,导致结果难以复现。
- 测试和调试困难:由于非确定性行为,测试和调试合作进程通常更加复杂和困难。
- 容易出现竞态条件(race conditions):合作进程容易受到竞态条件的影响,也就是进程的结果可能取决于其他进程事件的顺序或时间。
多个并发协同活动存在的原因:
在操作系统中,有多个并发活动需要同时进行,例如用户任务、系统任务、输入/输出操作等。这些活动可能需要共享资源、信息或数据,并且需要协同工作以实现系统的有效运行。
为什么不应该为每一个并发活动定义一个单独的进程:
虽然可以为每一个并发活动定义一个单独的进程,但这样做会带来一些问题和不便。下面是其中一些问题:
- 进程效率问题:创建新的进程是一项开销较大的操作,因为需要分配新的进程结构和资源。如果为每一个并发活动都创建一个新的进程,会导致资源的浪费和系统性能下降。
- 进程不直接共享内存:每个进程都运行在自己独立的地址空间中,不直接共享内存。这意味着如果并发活动需要访问和操作相同的数据,通常需要通过慢速的操作系统通信机制来进行通信,这会导致效率低下。
在操作系统中的进程
在操作系统中,每个进程都运行在其自己的独立地址空间中,这是非常重要的特性,被称为进程隔离。这意味着同一个地址在两个不同的进程中会被存储在内存中的两个不同位置,而不会互相干扰。
线程
引入线程的原因
考虑一个运行文件服务器的进程。偶尔,这个文件服务器进程需要等待硬盘响应。在这段等待时间内,该进程将被阻塞,无法响应新的请求。
为了加速将来的操作,该进程将在其内存中保持最近文件的缓存。在这种情况下,一个好的想法是同时运行第二个并发文件服务器来工作,而不是等待。
然而,通过创建两个独立的进程来实现并发并不是一种高效的方法。这是因为它们必须在相同的地址空间中运行,以有效地共享公共缓存。
解决上述问题的方法是引入线程的概念。线程是进程内的轻量级并发执行单元,它们在同一个进程内运行,并可以有效地共享相同的地址空间和资源。
在这种情况下,可以在同一个进程内创建多个线程,其中一个线程可以等待硬盘响应,而另一个线程可以继续工作并处理其他请求,例如维护缓存。这使得进程内的多个线程能够并发执行,而不需要为每个线程创建独立的进程。这提高了系统的性能和资源利用率。
因此,线程的引入允许在同一个进程内创建多个并发执行的实体,提高了处理并发任务的效率和响应能力。线程通常被用于多任务操作系统和应用程序中,以实现更好的并发性和资源共享。
进程和线程
现代操作系统通常同时支持进程和线程,这被称为多线程操作系统(multi-threaded OS)。
- 进程(Process):进程定义了一个独立的地址空间,以及一些通用的进程属性,如文件句柄、打开的文件、代码段等。进程是操作系统中的一个独立执行单元,每个进程都有自己的资源和状态,通常是程序的一个实例。
- 线程(Thread):线程定义了在进程内的单一顺序执行流。线程共享相同的进程地址空间和资源,但每个线程可以独立运行,并具有自己的栈和寄存器状态。线程是进程的一个子部分,多个线程可以在同一个进程内并发执行。
属于同一进程的线程共享几乎所有与该进程相关的资源:
- 地址空间(代码和数据)
- 全局变量
- 权限
- 打开的文件
- 计时器
- 信号
- 信号量
- 计费信息
- 然而,线程之间不共享以下内容:
- 寄存器集,特别是程序计数器(PC)、堆栈指针(SP)、中断向量
- 堆栈
- 状态
- 子线程
线程的特点
- 线程不能独立存在,它们始终属于一个进程,一个进程至少包含一个线程。
- 线程的创建相对便宜,因为不需要分配新的进程控制块(PCB)或创建新的地址空间。
- 线程可以通过进程的全局变量或共享内存以及简单的原语有效地相互通信。这增加了并发性,即使在单处理器系统中也很有用。
- 线程可以静态或动态创建,而且如果一个线程需要操作系统提供的服务(系统调用),它会代表所属的进程执行相应的操作。
线程的实现方式
用户空间线程(many-to-one模型):
在用户空间线程模型中,线程管理和调度完全在用户级别进行,而不涉及操作系统内核。在这种模型中,多个用户级线程共享同一个内核线程,也就是说,多个用户级线程运行在一个进程内,但它们只有一个内核线程来执行。
- 在用户空间线程模型中,操作系统内核调度的是进程,而不知道线程的存在。
- 每个进程维护一个线程表(thread table),进程自己决定在其运行时运行哪个线程。
优点:
- 单线程的操作系统可以模拟多线程。
- 线程调度由运行时库(run-time library)控制,没有系统调用的开销。
- 可移植性:可以实现独立于操作系统的用户空间线程库。
缺点:
- 如果一个用户级线程阻塞(例如,等待I/O),则整个进程都会阻塞,因为内核线程没有被释放。
- 不能充分利用多核处理器的并行性,因为内核线程数量有限。
内核空间线程(内核线程,one-to-one模型):
在内核空间线程模型中,每个用户级线程都有一个对应的内核线程。这意味着每个用户级线程都由内核管理和调度,因此更为独立。
- 在内核空间线程模型中,操作系统内核调度的是线程,线程是最小的调度单位。
- 操作系统维护系统范围的线程表,类似于进程表。
优点:
- 可以更好地管理线程,各线程之间独立。
- 提供更好的互动性。
缺点:
- 线程的创建和切换开销较大,因为需要内核的干预。
- 管理多个内核线程可能会导致更复杂的调度和资源管理。
混合模型(many-to-many模型):
混合模型结合了用户空间线程和内核空间线程的优点。在这种模型中,多个用户级线程可以映射到多个内核线程,以实现更好的并发性和性能。这种模型允许用户级线程在不阻塞整个进程的情况下等待I/O等操作。
进程同步(Process Synchronization)
并发执行
并发执行表示两个或更多进程或线程同时执行,它们可以共享资源并相互影响彼此的执行。
原子操作
它们在执行过程中不会被其他操作中断或分割为多个步骤。这确保了在执行原子操作时,操作的开始和结束都是不可分割的,不会发生在中间的中断或干扰。原子操作通常用于确保数据的一致性和避免竞争条件。
互斥与临界区
“Milk Problem” 是一个经典的示例,用来说明并发编程中的竞争条件和进程同步的概念。在这个问题中,有两个合租者共享一台冰箱,并希望冰箱中最多只有一瓶牛奶。
以下是这个问题的解释:
- 临界区(Critical Section):在这个问题中,临界区是一组操作,包括检查冰箱、去购物、将牛奶放入冰箱等。这些操作都涉及到共享资源(冰箱)的访问和修改。
- 互斥(Mutual Exclusion):为了解决这个问题,只能允许一个合租者(Flatmate A 或 Flatmate B)在任何时刻执行临界区的操作。这就是互斥的含义,它确保只有一个合租者可以操作冰箱,以防止多个合租者同时将牛奶放入冰箱,导致问题出现。
重要概念
- 同步(Synchronization):确保不同进程(或线程)之间进行适当的合作,依赖于原子操作,以避免竞争条件和数据不一致。
- 互斥(Mutual Exclusion,ME):确保在任何时刻只有一个进程可以持有或修改共享资源。互斥实现了操作的原子性。
- 临界区(Critical Section,CS):程序中的代码部分,其中对共享资源进行操作。互斥在临界区中的应用,要求对临界区的访问进行进程的串行化,以确保操作的原子性和正确性。
锁定
在并发编程中,实现临界区内的互斥性——锁定是一种方式,用于防止其他进程或线程在关键资源上执行某些操作,从而确保在任何给定时间只有一个进程或线程可以进入关键区域。
下面是关于锁定的规则:
- 进入临界区前必须锁定:在进入临界区之前,进程或线程必须先获取锁。只有当锁可用时,才能进入临界区。
- 离开临界区时必须解锁:在完成对临界区的操作后,进程或线程必须释放锁,以便其他进程或线程可以获得它并进入临界区。
- 尝试进入已锁定的临界区时必须等待:如果临界区已被其他进程或线程锁定,那么尝试进入该区域的进程或线程必须等待,直到锁被释放为止。
真正解决临界区问题的要求
- 互斥性(Mutual Exclusion):在任何给定时刻,至多只能有一个进程在临界区内执行。这确保了临界区的互斥性,防止多个进程同时访问或修改共享资源,从而避免竞争条件。
- 有界等待(Bounded Waiting):没有进程会无限期地等待进入临界区。这意味着如果一个进程尝试进入它的临界区,它最终会成功,而不会被无限期地推迟。这有助于防止死锁和饥饿(starvation)的情况。
- 进展性(Progress):一个在临界区外执行的进程不能阻止另一个进程进入它的临界区。如果多个进程同时尝试进入临界区,那么必须有机制来确保其中一个进程最终能够进入,而不是无限期地等待。此外,进程不能永远停留在临界区内,必须能够进入和离开。
互斥机制的理想特点
- 简单(Simple):互斥性机制应该是简单的,易于理解和使用。它们的使用不应该过于复杂,而是通过直接标记(例如,加锁和解锁)临界区来使用。
- 高效(Efficient):互斥性机制应该是高效的,不会占用过多的系统资源。这意味着它们不应该使用忙等待(busy-waiting)来浪费CPU资源,而且进入和离开临界区的开销应该尽可能小,以确保性能。
- 可扩展(Scalable):互斥性机制应该能够扩展到多个线程或进程共享临界区的情况。它们不应受到线程数量的限制,而应该能够适应不同规模的并发。
三种基本的互斥机制
- 信号量(Semaphores):信号量是一种低级机制,用于管理资源的访问。虽然它们可以实现互斥性,但它们相对难以使用,需要更复杂的编程。
- 监视器(Monitors):监视器是一种更高级的机制,通常需要高级编程语言支持。它们提供了更高层次的抽象,使并发编程更容易,同时实现了互斥性。
- 消息传递(Messages):消息传递是一种不依赖共享内存的互斥性机制。它使用进程间通信(IPC)消息而不是共享内存来实现同步。
信号量
信号量通常是一个受保护的整数变量,与一个等待进程队列相关联。它支持两种原子操作:P(等待)和V(释放)。
- 信号量变量 S:信号量是一个整数变量,它具有初始值,该值表示可以同时进入临界区的进程数量。
- 等待操作 P(S):P操作用于尝试减少信号量S的值。如果S的值大于零,那么它将减少S的值,允许进程进入临界区。如果S的值为零,那么该进程将被阻塞,并加入等待队列。
- 释放操作 V(S):V操作用于增加信号量S的值。如果有等待的进程,它将允许其中一个进程继续执行(从等待队列中取出一个),否则它将增加S的值。
实例
生产者/消费者问题(Producer/Consumer Problem)是一种常见的同步问题,通常用于描述多个进程或线程之间如何协同工作以生产和消耗资源。这个问题通常包括两种类型的进程:
- 生产者(Producer):生产者进程负责创建资源的实例。它生成资源并将其放入一个共享的缓冲区(或队列)中。
- 消费者(Consumer):消费者进程负责使用资源的实例。它从共享的缓冲区中取出资源并执行相应的操作。
约束
- 消费者必须等待生产者:如果缓冲区为空,消费者必须等待,直到生产者将资源放入缓冲区。
- 生产者必须等待消费者:如果缓冲区已满,生产者必须等待,直到消费者从缓冲区中取出资源。
cppCopy code
1 | |
监视器
监视器包括变量、过程(方法)以及条件变量。它们通常在一种特殊的结构内组织,用于管理并发访问共享资源。
监视器规则:
- 只允许一个进程在监视器内部活动,这确保了互斥访问共享资源。
- 互斥访问内部数据是由编译器来保证的,这意味着程序员不必显式编写互斥锁来保护监视器内部的数据。
调用监视器过程:
- 进程可以随时调用监视器内的过程来访问共享资源。当一个进程调用监视器过程时,它将进入监视器并获取互斥访问权限。
不能直接访问内部数据:
- 进程不能直接访问监视器内部的数据(如
i),而必须使用监视器内部的过程来访问或修改这些数据。这样可以确保数据的一致性和互斥性。
在监视器(Monitors)中,互斥性(Mutual Exclusion)通常是通过内部条件变量(Condition Variables)来实现的。条件变量是一种用于在多个进程或线程之间进行等待和通知的机制。下面是关于监视器中的条件变量以及与之关联的等待(Wait)和通知(Signal)操作的解释:
- 等待(Wait)操作: 等待操作是在监视器内部的条件变量上执行的。它通常在监视器发现某个进程无法继续执行时被调用。等待操作会导致调用它的进程被阻塞,并等待在条件变量上。这个操作的目的是将进程暂时挂起,以便其他进程可以获得进入监视器的权限。一旦进程调用等待操作,它就会被阻塞,直到其他进程发出通知(Signal)操作来唤醒它。
- 通知(Signal)操作: 通知操作用于唤醒等待在条件变量上的一个或多个进程。通知操作会让一个被等待的进程继续执行。值得注意的是,一旦调用通知操作,执行通知操作的进程必须立即退出监视器,以确保互斥性。这是因为通知操作的目的是唤醒等待的进程,而不是让执行通知的进程继续在监视器内执行,以避免竞争条件。
生产者和消费者问题
生产者负责将消息放入缓冲区,而消费者负责从缓冲区中移除消息。
这个监视器需要两个条件和一些内部数据来跟踪缓冲区的状态:
count:一个整数变量,用于跟踪当前缓冲区中的消息数量。full_s和empty_s:两个条件变量,用于通知生产者和消费者关于缓冲区状态的信息。full_s用于指示缓冲区已满,empty_s用于指示缓冲区为空。
1 | |
Monitor for Producer/Consumer 中的操作:
put(msg):这是生产者使用的操作,用于将消息放入缓冲区。- 如果
count等于缓冲区的最大容量N,表示缓冲区已满,生产者需要等待。此时,它会调用wait(empty_s),暂停并等待直到empty_s条件被信号(即缓冲区不再为空)。 - 一旦缓冲区有足够的空间,生产者将消息放入缓冲区,然后增加
count计数。 - 如果
count从0变成1(表示之前是空的),则会发出signal(full_s),通知任何等待在full_s条件上的消费者。
- 如果
get():这是消费者使用的操作,用于从缓冲区中取出消息。- 如果
count等于0,表示缓冲区为空,消费者需要等待。此时,它会调用wait(full_s),暂停并等待直到full_s条件被信号(即缓冲区不再满)。 - 一旦缓冲区中有消息,消费者从中取出消息,然后减少
count计数。 - 如果
count从N减少到N-1(表示之前是满的),则会发出signal(empty_s),通知任何等待在empty_s条件上的生产者。
- 如果
生产者代码:
1 | |
在这段代码中,生产者不断循环生成消息,然后调用 pr_co.put(msg) 将消息放入缓冲区。
消费者代码:
1 | |
在这段代码中,消费者也不断循环,调用 pr_co.get() 从缓冲区中取出消息,然后对消息进行处理(通过 consume_msg(msg) 函数)。
消息系统
组成要素: 消息(message): 在两个及以上进程或线程间交换信息
邮箱 (mailbox):在消息发送和接受之间储存消息的地方
消息系统的基本操作:
send(mailbox, message): 把消息放入邮箱
receive(mailbox, message): 从邮箱中删除邮件
create(mailbox)
delete(mailbox)
消息系统的寻址方式:
消息系统的寻址方式是通过进程ID(PID)来标识源和目标进程。PID是一个唯一的标识符,用于标识正在运行的进程。当一个进程向另一个进程发送消息时,它将消息标记为源进程的PID,并将目标进程的PID作为消息的目标。这样,目标进程就可以通过其PID识别消息的来源,并采取适当的措施。如果有多个目标,或者目标未指定,则可以使用其他标识符来标识目标进程。
消息格式
- 固定长度:减少处理和储存的开销
- 可变长度:更适合消息系统
阻塞与非阻塞
阻塞发送:进程发送信息后,它会一直阻塞,直到消息被接受
非阻塞发送:在消息发送后,发送方继续工作,无需等待
阻塞接受:进程执行接受时,它会被阻塞,直到接收到信息。
非阻塞接受:进程执行接受,无需等待接受到消息。
最常见的组合是:非阻塞发送和阻塞接受
消息执行互斥:
当进程接收到消息时,它可以进入临界区。
当进程离开临界区时,他必须向邮箱发送新消息。
死锁( Deadlock) 与饥饿(Starvation)
死锁
在死锁状态下,每个进程都在等待其他进程释放它们所需的资源,但没有一个进程愿意放弃自己已经获取的资源,因此所有进程都无法继续执行。
- 互斥条件:资源只能被一个进程占用。
- 请求与保持条件:进程可以请求额外的资源,同时保持已经分配的资源。
- 不可剥夺条件:资源只能在进程自愿释放时才能够被回收。
- 循环等待条件:多个进程之间形成一个等待资源的循环链。
饥饿
一个进程由于某种调度策略而无法获得所需的资源,即使资源周期性地可用。这意味着进程被不公平地排除在资源分配之外,无法继续执行。饥饿通常发生在以下情况:
- 优先级倾斜:低优先级进程一直在等待,但高优先级进程总是优先获得资源。
- 锁定竞争:多个进程竞争相同的资源,但某些进程可能因竞争激烈而无法获得资源。
资源(resources)
可重用资源(Reusable resources)
可重用资源(Reusable resources)是那些可以同时被一个进程占用,而且在使用后不会被消耗的资源。这意味着多个进程可以依次使用相同的可重用资源,而资源在使用后并不会减少或损坏,因此可以被其他进程再次使用。以下是关于可重用资源的一些重要特点:
- Resources used by only process at a time, and not depleted by that use.
- After use, they are released for reuse by other process.
- Example: Processors, Main memory, devices, semaphores
- 可同时使用:多个进程可以同时请求并使用可重用资源,而这些资源不会发生冲突。
- 不会被耗尽:使用可重用资源不会导致资源的数量减少,它们仍然可以在未来被其他进程使用。
- 释放后可以再次使用:当一个进程使用完可重用资源后,它会释放这些资源,以供其他进程使用。
- 例子:可重用资源的示例包括处理器(CPU)、主存和辅助存储设备、各种外部设备,以及数据结构如数据库和信号量。
可消耗资源(Consumable Resources)
可消耗资源是由一个进程生成或产生的,然后传递给其他进程,最终由接收资源的进程消耗或销毁。这些资源通常用于进程之间的通信或协作。
- Resources created by one process and destroyed by another
- Infinite number of instances
- No need to release
- Example: signals, interrupts, message
- 有无限数量的实例:可消耗资源通常可以有无限多的实例。这意味着可以不断地创建和消耗这些资源,而不会耗尽它们。
- 无需显式释放:与可重用资源不同,可消耗资源通常无需显式释放。一旦资源被使用并消耗,它们可以自动被系统回收或销毁。
- 示例:可消耗资源的示例包括信号(Signals)、中断(Interrupts)、消息(Messages)等。这些资源用于进程之间的通信和协作,例如,一个进程可以向另一个进程发送信号或消息,以通知它发生了某些事件或需要执行某些操作。
可重用资源导致死锁的示例
在这个示例中,有200MB的内存可供使用,并且有两个进程,P1和P2,它们都请求分配一些内存。
- 初始请求:P1和P2都请求了一些内存,它们的请求都被满足(Request 80MB和Request 70MB)。此时,200MB的内存中还有剩余。
- 同时第二次请求:问题出现在第二次请求,当P1和P2同时请求额外的内存(Request 60MB和Request 80MB)。由于它们同时请求内存,它们都会尝试占用未释放的初始请求内存。
- 初始内存请求未释放:由于初始内存请求并没有被释放,内存资源不足以满足这两个同时进行的第二次请求。每个进程都需要等待对方释放内存,以便满足自己的第二次请求。
- 结果是死锁:在这种情况下,由于两个进程都无法获得所需的内存,它们都被阻塞,等待对方释放内存,这导致了死锁。没有进程愿意主动释放内存,因为它们都在等待对方的释放。
可消耗资源(以message为例)导致死锁
- 进程依赖:P1需要接收P2发送的消息(N),而P2需要接收P1发送的消息(M)才能继续执行。这创建了一种相互依赖关系,其中每个进程等待另一个进程发送消息以满足它的接收操作。
- 同时操作:问题出现在当P1和P2同时尝试执行
receive操作时,这两个操作都是阻塞的,因为它们等待对方发送消息。 - 结果是死锁:由于P1和P2都无法继续执行,它们被阻塞在
receive操作上,等待对方发送消息。这导致了死锁,因为没有一个进程愿意主动发送消息,因为它们都在等待对方的消息。
Philosophers"(用餐哲学家)问题。问题的背景是,有5位哲学家围坐在一张圆桌旁,每位哲学家要么在思考,要么在用餐。在桌子上有5碗面条和5个叉子,每位哲学家需要同时拿到他们面前的两个叉子才能用餐。然而,只有一个哲学家可以同时使用一个叉子。
为了解决这个问题,文本提供了一个解决方案,使用信号量来控制资源的分配和哲学家的行为。下面是一些关键点的解释:
- 信号量解决方案:为了控制资源的访问,每个叉子都有一个信号量,初始值为1,表示叉子是否被占用。另外,还有一个名为
table的信号量,其初始值为4,表示最多允许4位哲学家同时坐在桌子旁。 - 哲学家的行为:每位哲学家都是一个进程,它们以循环的方式执行以下行为:
- 思考:哲学家思考一段时间。
- 尝试获取左边的叉子(
P(fork[i]))。 - 尝试获取右边的叉子(
P(fork[(i+1) mod 5]))。 - 吃面条:如果成功获得了两个叉子,那么哲学家可以用餐。
- 释放叉子:用餐后,哲学家释放叉子(
V(fork[(i+1) mod 5])和V(fork[i]))。 - 释放桌子:哲学家用餐完毕后,释放桌子(
V(table)),以便其他哲学家可以用餐。
- 死锁和饥饿问题:文本提到,最初的解决方案可能会导致死锁,因为所有哲学家在同一时刻都尝试获取左边的叉子。为了解决死锁,可以添加机制,使哲学家在获取左边的叉子时,如果右边的叉子已经被占用,则释放左边的叉子并等待一段时间后再尝试。这样,死锁问题得到解决。
- 饥饿问题:即使死锁问题得到解决,仍然存在饥饿问题,因为如果所有哲学家在同一时刻都开始执行算法,它们可能会陷入无限循环。为了解决饥饿问题,可以引入随机等待时间,以确保哲学家们在不同时间尝试获取叉子,从而减少竞争。
提到了一些可能的解决方案,以应对死锁和饥饿问题,这些问题通常出现在"Dining Philosophers"问题中。这些解决方案包括:
- 限制哲学家的数量:一种简单的解决方案是限制在桌子旁的哲学家数量,以降低资源争夺的概率。例如,可以只允许最多四位哲学家同时坐在桌子旁,这样至少有一位哲学家能够吃饭,而不会导致死锁。
- 不对称解决方案:在不对称解决方案中,哲学家的行为被设定为不同,以减少资源竞争。例如,偶数编号的哲学家可以首先尝试获取左边的叉子,而奇数编号的哲学家可以首先尝试获取右边的叉子。这样可以减少争用,但仍需要适当的资源分配。
- 使用计数信号量:另一种解决方案是为每位哲学家提供一个计数信号量,用于跟踪可用的叉子数量。这需要小心的初始化,以确保适当的资源分配,以避免死锁和饥饿。
- 形式化建模:最终,为了更好地处理这个问题的复杂性,可以采用形式化建模方法,例如Petri网、模型检测等,来分析和验证不同解决方案的正确性。这可以帮助确保哲学家问题的解决方案是可靠和健壮的。
资源分配图(Resource-Allocation Graph,RAG)
资源分配图(Resource-Allocation Graph,RAG)是一种用于更形式化地描述死锁的方法,通常用于分析和识别系统中的死锁情况。RAG是一个有向图,它用于表示资源分配和进程等待的情况
- 图的组成:
- 顶点(节点)集:资源分配图包括一组顶点,每个顶点通常代表一个进程或一个资源。
- 边(连接顶点的线)集:边表示资源分配和等待的关系。
- 顶点表示:
- 顶点可以代表两种不同的实体:
- 进程:每个进程由一个顶点表示,表示该进程正在运行或等待资源。
- 资源:每个资源也由一个顶点表示,表示该资源当前是否被分配给某个进程。
- 顶点可以代表两种不同的实体:
- 边表示:
- 边表示资源的分配和等待关系。
- 分配边:当一个资源被分配给一个进程时,从资源的顶点到进程的顶点绘制一条边。
- 等待边:当一个进程等待获取一个资源时,从进程的顶点到资源的顶点绘制一条边。
- 边表示资源的分配和等待关系。
- 图的状态:
- 资源分配图完全描述了系统的状态,包括哪些资源被分配给哪些进程,以及哪些进程正在等待哪些资源。
- 检测死锁:
- 通过分析资源分配图,可以检测潜在的死锁情况。如果图中存在环(循环等待),那么系统可能处于死锁状态。
进程调度
- 进程调度是指在一个多任务操作系统中,当一个进程完成执行或者由于等待I/O操作而暂停时,操作系统需要决定接下来应该执行哪个进程。
- 这是一个复杂的决策,因为通常系统中会有多个进程等待执行,而CPU数量有限。因此,需要一个组件来负责这一决策,这个组件被称为调度程序(Scheduler)。
- 调度程序基于一定的调度算法来做出决策。这些算法定义了在什么情况下应该选择哪个进程来运行,以及每个进程运行的时间片。
- 有许多不同的调度算法可供选择,每个算法都有其自己的优点和局限性,因此选择适当的调度算法对于系统性能非常重要。
突发周期
CPU Burst(CPU突发):
A period of CPU execution with no I/O
- CPU Burst是进程在执行过程中的一段时间,期间CPU被用于计算和执行指令,而没有进行输入/输出操作(I/O)。
- 在CPU Burst期间,进程正在执行计算任务,进行数学运算,或执行其他需要CPU计算资源的操作。
I/O Burst(I/O突发):
Wait for I/O signal
- I/O Burst是进程在等待I/O操作完成时的状态。在这个状态中,进程暂停CPU的使用,等待某种I/O操作的信号或完成。
- 通常,在I/O Burst期间,进程会暂停执行,并将CPU资源释放给其他进程,以便系统可以更高效地利用CPU。
Burst cycles的交替发生通常是进程执行的一部分,进程在CPU Burst和I/O Burst之间切换,以完成不同的计算和I/O任务。这种交替可以确保系统中的多个进程都能得到处理,提高系统的并发性和资源利用率。
In multiprogramming, mix the CPU and I/O brust of different process to increase utilisation. When one process is waiting we execute another process.
调度器类型
长期调度器(Long-Term Scheduler):
A program becomes a process once selected by long-term scheduler, and it is added to the ready queue. Long controls the degree of mutiprogramming.
- 长期调度器控制了被允许竞争系统资源的进程池。它决定将哪些程序(通常是从外部提交的)变成进程,并将它们添加到就绪队列(ready queue)中,以便它们能够参与CPU资源的竞争。
- 长期调度器控制多道程序设计的程度,即决定系统中同时运行的进程数量。增加进程数量会导致每个进程能够分配到的CPU时间较少,但也提高了系统的并发性。
中期调度器(Medium-Term Scheduler):
Select what processes are kept in memory, actively competing for CPU acquisition.
- 中期调度器负责选择哪些进程将保留在内存中,以积极竞争获取CPU资源。中期调度器充当了一个缓冲区,可以暂停和恢复进程,以调整系统的负载。
- 中期调度器的作用是确保系统中的内存资源得到有效利用,并根据需要将进程从内存中移除,以便为新进程腾出空间。
短期调度器(Short-Term Scheduler):
Select what process is assigned to CPU
Only selects from processes in the ready queue.
- 短期调度器负责从就绪队列中选择下一个应该分配给CPU的进程。它只能从已准备好竞争CPU资源的进程中进行选择。
- 短期调度器的作用是在内存中已准备好执行的进程中,选择一个来运行,以实现多任务并行执行。
这些不同的调度器在操作系统中起着不同的作用,长期调度器控制多道程序设计的程度,中期调度器管理内存中的进程,而短期调度器负责选择下一个要运行的进程,以确保系统的高效性和响应性。
调度队列
就绪队列(Ready Queue):
Queue of all processes that are eligible to be scheduled.
- 就绪队列包含了所有具备条件被调度执行的进程。这些进程已经准备好运行,只需要分配CPU资源就可以立即开始执行。通常,短期调度器(Short-Term Scheduler)从就绪队列中选择下一个要执行的进程。
就绪-暂停队列(Ready-Suspended Queue):
Queue of all processes that are ready to be execute but have been excluded by the medium.
- 就绪-暂停队列包含了那些已准备好执行但由于一些原因被中期调度器(Medium-Term Scheduler)排除在外的进程。这些进程可能暂时不在内存中,或者由于某些原因被暂停。它们可以在稍后重新加入就绪队列。
阻塞队列(Blocked Queue):
Queue of all processes that are waiting for an event before going to ready queue.
- 阻塞队列包含了那些正在等待某个事件发生的进程,然后才能继续执行。这些事件可能包括I/O操作完成、信号接收等。进程在等待事件发生时被移动到阻塞队列。
阻塞-暂停队列(Blocked-Suspended Queue):
Queue of all processes that are waiting for an event and have been excluded by the medium.
- 阻塞-暂停队列包含了那些正在等待事件发生的进程,但由于一些原因被中期调度器排除在外。这些进程可能暂时不在内存中,或者由于其他原因被暂停。它们可以在稍后重新加入阻塞队列。
这些调度队列在多任务操作系统中用于有效地管理和组织进程的执行。不同类型的队列允许操作系统将进程分类,以便根据各种条件和需求来做出决策。例如,短期调度器从就绪队列中选择进程以执行,中期调度器可能会在就绪-暂停队列和阻塞-暂停队列之间移动进程以优化系统负载,同时在阻塞队列中等待事件的进程则在事件发生后重新移动到就绪队列。
分派程序(Dispatcher)
- 分派程序是一个操作系统组件,它的任务是在短期调度器选择下一个要执行的进程后,负责执行上下文切换,将CPU控制权分派给新的进程。
- 分派程序必须尽可能快,因为它在每次进程切换时都会被调用。分派程序的性能直接影响系统的响应时间和效率。
分派程序的功能:
- 切换上下文(Switch context):分派程序将正在运行的进程的上下文保存到进程控制块(Process Control Block,PCB)中,然后将将要运行的进程的PCB内容加载到内存中,以准备执行。
- 存储相关数据:分派程序需要保存和恢复与进程执行相关的所有必要数据,以确保进程能够在下次运行时继续其执行。
- 跳转到程序的正确位置( Jump to the right location in the program to restart it, switching to user/ kernel mode if required.:分派程序必须确保控制权移交给新进程后,它从程序的正确位置开始执行。这可能涉及到切换用户模式和内核模式,具体取决于操作系统的设计和保护机制。
分派延迟(Dispatch Latency):
- 分派延迟是指在短期调度器(Short-Term Scheduler)选择下一个要执行的进程后,需要经过一系列步骤才能将控制权分派给该进程的时间延迟。
- 分派延迟包括以下步骤:
- 获取新进程执行所需的资源。Gets the resources needed to execute the new process
- 如果正在运行的进程只应在运行时拥有某些资源,需要将这些资源从运行中的进程中剥夺(资源抢占)。Preemption of running process resources.
- 分派程序(Dispatcher)执行切换上下文的操作,以将CPU控制权移交给新选定的进程。
- 获取新进程执行所需的资源。Gets the resources needed to execute the new process
调度策略
非抢占式调度(Non-preemptive Scheduling):
- 非抢占式调度是一种调度策略,其中调度决策只在进程自愿释放CPU控制权时才会发生。也就是说,进程只在主动让出CPU时,才会进行调度切换。
- 这种调度策略可能导致以下特点和影响:
- 短时间的进程可能会经历长时间的延迟,因为长时间运行的进程不会被强制停止。
- 从进程提交到完成的时间可能会变得难以预测,因为没有预定的时间片用于强制切换进程。
- 错误或恶意进程可能会阻塞系统,因为它们不会自愿释放CPU。
抢占式调度(Preemptive Scheduling):
抢占式调度是一种调度策略,其中进程可以被强制从正在运行的CPU中移除,以分配给另一个进程。这可以发生在预定的时间片结束、高优先级进程到来、或发生某些特定事件时。
这种调度策略带来了以下特点和影响:
- 恶意或错误的进程可以被强制从CPU中移除,以确保它们不会无限期地占用CPU资源。(Malicous or errant processes can be removed from the CPU)
- 改善了响应时间,特别适用于交互式系统和时间共享系统,因为可以及时地响应用户的输入。(Improved response times are possible)
- 对于软实时系统而言,抢占式调度是必要的,因为它可以确保紧急任务及时完成。然而,对于硬实时系统,通常不使用抢占,因为它们需要更加确定的响应时间保证。
抢占式调度允许操作系统更好地管理CPU资源,及时响应紧急情况,但也需要更多的调度开销。非抢占式调度在某些情况下可以更简单,但可能导致不可预测的系统行为。
调度目标
- 最大化处理器利用率(Maximise processor utilisation)。
- 最大化吞吐量(Maximise throughput),即单位时间内完成的进程数量。
- 最小化就绪队列中的等待时间(Minimise waiting time in the ready queue)。
- 最小化响应时间(Minimise response time),即首次获得CPU的等待时间。
- 最小化周转时间(Minimise turnaround time),包括等待时间和执行时间。
- 满足进程的截止日期(Complete processes by given deadlines)。
不同的调度目标通常无法同时实现,因此操作系统调度算法通常专注于目标的子集,以平衡性能需求。
无论采用何种调度策略,都应具备以下特点:
- 政策执行(Policy enforcement):确保系统的调度策略得以执行。
- 公平性和平衡性(Fairness and Balance):确保没有进程被饿死(starved),并且相似的进程受到相同的对待。No process is starved. Similar processes are treated the same.
- 可预测性(Predictability):在相似负载下,相同进程应在大致相同的时间内运行。
- 可扩展性(Scalability):在重负载下能够实现优雅的性能降级。
为了实现调度目标,调度程序还应考虑进程的行为。进程行为通常根据其CPU突发模式进行分类。
常见的进程分类包括:
- CPU密集型(CPU-bound):通常会占用大部分CPU时间。
- I/O密集型(I/O-bound):通常会频繁生成I/O请求并释放处理器。
大多数进程现在倾向于是I/O密集型,因为CPU技术进步较快,而磁盘技术进展相对较慢。
典型进程(Typical Processes):
- 进程通常根据其活动性进行分类,包括批处理进程(Batch Process)和交互式进程(Interactive Process)。
- 批处理进程通常是CPU密集型,不需要用户输入,而交互式进程通常是I/O密集型,需要频繁的用户输入。
对于批处理系统,吞吐量(throughput)和周转时间(turnaround time)是重要的。
对于交互式系统,响应时间(response time)是关键。
调度算法
FCFS
Implements FIFO
FCFS is good for CPU-bound processes
But the waiting time is bad if long processes come first.

Shortest Job First
Always schedule the process with the shortest upcoming burst time next.
2 version:
- Non-preemptive - Shortest Job First
- Preemptive - Shortest Time Remaining Firest
If all processes arrive at the same time, Non- preemptive is better.
Exponential Average
t~n~ be the measured length of the n-th CPU burst.
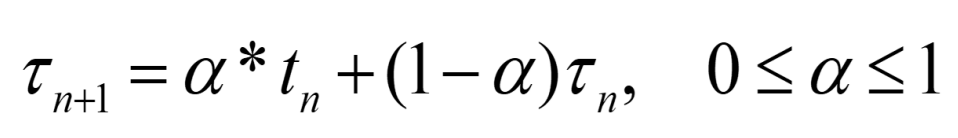
If a = 0, then recent times have no effect.
If a = 1, only the most recent CPU burst is considered.
Usually a is 0.5
Round Robin
Processes are dispatched FIFO but only given a limited amount of CPU time. (Called a time slice)
RR performance heavily depends on the time slice size.
Priority Scheduling
We schedule the most important processes first.
Small numbers mean high priority.
Starvation
Low priority proesses might never execute, we need to increase priority as time progresses(ageing)
Multilevel Queue Scheduling
Lottery Scheduling
Lottery scheduling is an adaptive scheduling approach to address the fairness problem.
- Each process owns some tickets
- On each time slice, a ticket is randomly picked.
Scheduling in Real-Time Systems
Must meet the needs of processes that must produce correct output by a deadline.
SJF is optimal for the average waiting time, but it does not guarantee a fixed waiting time for any process.
Soft Real-Time Scheduling
Missing an deadline occasionally is acceptable.
Priority scheduling required. Small dispatch latency required.
Hard Real-Time Scheduling
Absolute deadline that always have to be met.(air traffic control)
内存管理
储存单元 (MU)
- 存储单元是指可以表示为大型数据字或字节数组的存储设备,每个数据都有其独特的物理地址。
- 存储单元的示例包括随机存取存储器(RAM)、闪存和磁盘存储。
- 需要注意的是,存储单元本身并不负责生成它所使用的地址。
多道程序设计操作系统中存储的作用:
Memory is central to the multiprogramming OS, since a process must be in memory to execute.
- 在多道程序设计中,多个进程同时加载到内存中,操作系统必须管理它们的执行。
- 为了执行进程,它必须存在于内存中。存储单元存储了进程运行所需的程序指令和数据。
指令执行循环:
- 加载指令: CPU通过从内存加载程序指令来启动指令执行循环。加载的指令的地址由程序计数器(PC)寄存器的内容决定,该寄存器跟踪下一条要执行的指令。
- 解码指令(decoded): 一旦加载,CPU对指令进行解码。解码涉及解释指令并确定其需要执行的操作。
- 内存操作: 指令的执行可能涉及从内存中额外加载或存储数据。这反映了程序执行的动态性,其中在进程过程中经常需要从内存获取数据,并将其存回内存。
- 进程终止(terminate): 最终,正在执行的进程将终止。当这发生时,它在内存中占用的空间被声明为空闲,允许操作系统加载和执行其他进程。
地址绑定
- 一个程序通常以二进制可执行文件的形式存储在磁盘(disk)上。
- 为了执行该程序,它必须被加载,即被引入到内存中,放置在进程地址空间的代码段中。
- 在具有虚拟内存的系统中,进程(或其部分)在执行期间可以在内存和磁盘之间移动(交换)。
大多数系统允许用户进程在内存单元的任何空闲位置驻留:
- 因此,进程的第一个物理地址不一定是0。
- 由于这个原因,需要一种地址绑定机制(address binding mechanism),使程序中使用的地址与正确的物理地址相关联。
在这个背景下,地址绑定的目的是确保程序中使用的地址能够正确地映射到物理内存中的位置。因为程序可能在执行过程中从磁盘加载到内存,地址绑定机制必须能够动态地调整这些地址,以便它们正确地指向正在执行的程序的位置。这有助于确保程序在执行过程中能够正确地访问其代码和数据。
地址绑定时机
1. 编译时(较早的系统):
- 如果进程的内存位置在编译时是已知的,编译器可以生成程序可执行文件中的绝对代码(absoulute code)_。在这种情况下,程序中的地址引用也是物理地址。
- 但是,如果进程位置发生变化,就需要重新编译程序(使用新地址)。
2. 载入时(较早的系统):
- 如果在编译时内存位置是未知的,编译器将符号地址绑定到可重定位地址(即偏移量)。
- 物理地址在载入时绑定。
- 如果进程位置发生变化,无需重新编译程序,但如果位置发生变化,则必须重新加载程序。
3. 执行时(现代通用操作系统):
- 如果在执行期间进程可以移动到另一个内存区域,那么绑定必须在运行时进行(动态绑定)。
- 需要特殊的硬件来将进程地址转换为物理地址,这就是内存管理单元(MMU)的作用。
Example
使用了"Base and limit registers"(基址寄存器和限制寄存器)来管理进程的地址空间.
基址寄存器和限制寄存器:
- 基址寄存器(Base Register): 它存储了一个进程可以访问的最小物理地址。也就是说,当一个进程要访问内存时,其地址将与基址相加,从而得到实际的物理地址。
- 限制寄存器(Limit Register): 它存储了进程地址空间的大小。通过这个限制,系统可以确保进程只能访问其地址空间内的有效范围。
地址翻译过程:
- 当运行中的进程生成一个内存地址 m 时,该地址通过基址寄存器进行翻译,即最终的物理地址为 m + 基址。
- 这个地址翻译是由内存管理单元(MMU)执行的硬件操作,它能够实时地将进程生成的逻辑地址翻译为实际的物理地址。
- 如果 m 大于等于限制寄存器中的限制值(即超出了进程的地址空间),则会触发地址错误陷阱。
特权指令和内核模式:
- 基址寄存器和限制寄存器的设置只能通过特权指令完成,而这些指令通常只能在内核模式下执行。
- 内核模式是操作系统运行的高特权级别,可以执行一些对系统关键部分进行管理的操作。
逻辑地址与物理地址空间:
逻辑地址(Logical Address): 由CPU处理,通常对应于进程的地址空间中的位置。
例如,一个32位处理器处理32位长的地址,进程的地址空间范围通常在0到2^32 - 1之间。
在编译时和载入时地址绑定中的逻辑和物理地址:
- 在编译时和载入时地址绑定时,逻辑地址和物理地址是相同的。
在运行时地址绑定(现代系统)中的逻辑和物理地址:
- 在运行时地址绑定时,逻辑地址和物理地址不同。
使用基址和限制寄存器的系统示例:
- 在使用基址和限制寄存器的系统中,逻辑地址通过基址寄存器进行转换,最终得到物理地址。
举例说明:
- 假设基址寄存器的值是B,逻辑地址为L,那么物理地址就是 B + L。
- 如果逻辑地址超出了限制寄存器指定的范围,就可能会触发错误
内存管理(MM)的重要性:
- 内存管理在计算机系统中是至关重要的。
- 理想情况下,我们希望拥有无限大且速度极快的非易失性内存。(infinitely large and infinitely fast non-volatile memory)
- 然而,在实际的计算机中,通常存在内存层次结构(memory hierarchy).
内存层次结构:
- 主存储器(Primary Memory): 相对较小但速度较快的易失性内存,如RAM(随机存取存储器)和缓存,也称为主存储器。
- 辅助存储器(Secondary Memory): 大量但速度较慢的非易失性内存,如硬盘和闪存。
- 第三级存储器(在一些特殊系统中): 存储在计算机外部,但仍然可访问,例如百度云盘。
内存管理的角色:
内存管理器:
操作系统的组件,负责以下任务:
- 跟踪哪些内存部分正在使用,哪些未被使用. Keep track of which parts of memory are in use and which parts are not.
- 在进程需要时分配内存,当进程完成时释放内存。Allocates memory to processes when they need it and deallocate it when they are done.
- 在主存储器无法容纳所有进程时,在主存储器和磁盘之间进行交换管理。Manages swapping between main memory and disk when the main memory cannot hold all processes.
内存管理系统:
- 内存管理系统可以分为两类:
- 单道程序设计(Monoprogramming): 一次只能执行一个程序。
- 多道程序设计(Multiprogramming): 允许多个程序同时在内存中执行。
单道程序设计(Monoprogramming)
特点:
- 非常简单: 一次只有一个用户进程在内存中(包括操作系统进程时可能为两个)。
- 内存管理仍然存在: 即使只有一个进程,内存管理仍然需要决定进程的数据将存储在何处。
- 缺乏保护: 单道程序设计通常缺乏对内存的保护机制,即进程不能访问其他进程的内存空间。
- 缺乏绑定和交换: 通常没有编译时或载入时的地址绑定,也没有进程之间的交换。
单道程序设计中的内存组织示例: 在单道程序设计中,内存的组织相对简单,因为只有一个用户进程在执行。以下是一些可能的内存组织示例:
- 顺序存储: 用户程序的指令和数据按顺序存放在内存中。
- 分区存储: 将内存划分为不同的区域,例如代码区、数据区等,以便存储用户程序的不同部分。
- 堆栈结构: 使用堆栈来管理函数调用和局部变量,使得程序的执行具有明显的结构。
多道程序设计(Multiprogramming):
特点:
旨在同时为多个用户提供交互式服务。Provide interactive services to seveal users simultaneously.
- 允许一次在内存中运行多个进程。
- 提供保护、运行时绑定和交换(使用分页/分段等技术,稍后会详细说明)。protection, run-time binding and swapping
目标是尽可能使处理器一直繁忙。
- Execute and not execute according to process state(I/O or not).
Muiltiprogramming increases CPU utilisation.
多道程序设计和性能:
- 当有n个进程在内存中时,其多道程序设计的程度为n。
- 假设任何进程花费其时间的一部分p等待I/O操作完成(0 < p < 1)。
- 所有n个进程都被阻塞等待I/O的概率为p^n。
CPU利用率的计算:
- CPU利用率 = 1 - p^n^,即1减去所有n个进程都等待I/O的概率。
多道程序设计 Performance:
- 多道程序设计提高了CPU的利用率,因为在一个进程等待I/O的时候,其他进程仍然可以在CPU上执行。
- 通过保持处理器忙碌,系统可以更有效地利用计算资源。
性能与交互式服务:
- 多道程序设计的目标之一是为多用户提供交互式服务,确保系统对多个用户的响应是及时的。
- 通过在等待I/O操作的进程之间切换执行不执行I/O的进程,系统可以更快地响应用户的请求。
案例:多道程序设计与性能: 尽管前述模型较为简化(它假设进程是独立的,I/O阻塞的概率相同等),但它使我们能够进行具体的性能预测。
假设:
- 考虑一台计算机,有1 GB内存,其中操作系统占用200 MB,留出空间可以运行四个占用200 MB的进程。
- 假设I/O等待时间为80%。
性能预测:
- 如果我们忽略操作系统执行开销,我们将实现略低于60%的CPU利用率。
- 如果我们再添加1 GB内存,我们可以运行另外五个进程;此时我们现在可以实现约86%的CPU利用率(性能提高了26%)。
- 但是,如果我们再添加1 GB内存(总共14个进程和1个操作系统),CPU利用率仅会增加到约96%(性能提高了仅为10%)。
这个案例说明了添加内存对系统性能的影响,并显示了性能提升可能会随着系统资源的增加而减缓。在实际系统中,性能受到许多因素的影响,包括硬件能力、操作系统的优化、应用程序的特性等。
内存组织
- 连续分配(Contiguous Allocation):
- 固定分区(Fixed Partitions): 将物理内存静态划分为若干分区,分区大小不一定相等。
- 可变分区(Variable Partitions): 动态划分内存,根据进程需求动态分配。
- 非连续分配(Non-contiguous Allocation):
- 固定块(Paging): 将内存划分为相等大小的块,可以在内存中分散,不一定是相邻的。
- 可变块(Segmentation): 将内存划分为可变大小的块,每个块内的地址仍然是连续的,但不同块之间的地址可以是非连续的。
固定分区:
- 单输入队列: 如果一个分区变为空闲,将其分配给下一个适合的等待队列中的进程。
- 多输入队列: 新的进程放置在可以容纳它的最小分区的队列中。
- 多输入队列 of 不同大小: 队列中的进程必须等待,直到其分区可用。
固定分区的优缺点:
- 优势: 在批处理系统上实现简单且有效。Simple implementation and effective on batch system.
- 劣势:
- 内部碎片化问题:由于分区大小固定,某个进程未使用的空间将会丢失。Internal fragmentation problem.
- 多输入队列可能导致性能大幅下降,因为大分区可能为空,但小分区可能队列已满。Loss of performance.
- 不考虑动态行为。Does not account for dynamic behaviour.
可变分区:
- 优势: 可变分区允许更大的适应性。adaptability
- 系统保留一个指示内存空闲部分的表。
- 进程的大小得到考虑,如果有足够的可用连续空间,则被分配。
- 分区的数量、位置和大小根据系统中运行的进程动态变化。
- 缺点:
- 外部碎片化问题:完成的进程可能会留下许多内存间隙。External fragmentation problem
- 对于新进程可能没有足够的自由连续内存,尽管碎片总量很大。这个问题可以通过压缩(compaction)来解决。
分页技术 (Paging):
基本策略:
- 物理内存被划分为小而相等的固定大小块(称为帧)。
- 逻辑内存(即进程的地址空间)也被划分为与帧相同大小的块(称为页)。
- 为了执行一个进程,它的页从磁盘加载到可用的内存帧中,依赖于一个页表。
加载程序:
- 如果有足够的空闲帧,程序可以加载。
- 也可以只加载执行所需的几页(虚拟内存)。
分页技术的特点:
碎片化 (Fragmentation):
- 内部碎片:仅为进程的最后一页的一小部分。
- 外部碎片:没有(不需要压缩)。
每个逻辑地址(即CPU或进程地址)被分为两部分:
- 页号和页内偏移。
页的大小通常是2^n^(例如,512字节-16 MB);如果逻辑地址空间的大小是2^m^,则:
- m - n位给出页号。
- n位给出页内偏移。
使用处理器硬件将逻辑地址转换为物理地址。
分页硬件:
小型页表:
- 如果页表较小(例如,256个条目),可以使用专用寄存器来实现。 dedicated register
分页硬件优化:
页表通常很大,保存在主内存中,但这对于使用寄存器来说速度较慢。
为了提高性能,使用
转换查找缓冲器(TLB)
:
- TLB是一个关联高速内存,将一个键(标签)与一个值关联。
- 当提供一个键时,它会同时与所有键进行比较。
- 需要替换策)。
- TLB的大小通常在64到1024个值之间。
TLB的性能分析:
- 使用带有TLB的分页系统的性能分析可以通过命中比率完成,即页面号在TLB中找到的时间比例。
- 有效内存访问时间(Te)的计算公式:
- T~e~ = p × (T~t~ + T~a~) + (1 − p) × (T~t~ + 2T~a~)
- p:命中概率(例如,如果命中比率为80%,则p = 0.8)
- T~t~:TLB访问时间
- T~a~:内存访问时间
- TLB成本较高。
总结: 分页技术通过将物理内存和逻辑内存划分为等大小的块来提供一种有效的内存管理方法。这可以减小内存碎片化,使程序更容易加载和运行。逻辑地址的划分和转换通过硬件支持,从而使得分页技术能够以较低的开销实现。
分段技术(Segmentation)
基本策略:
- 逻辑内存被划分为若干段,每个段的长度可能不同。
- 现在,逻辑地址由段号和段内偏移组成。
- 逻辑地址和物理地址之间有更复杂的关系。
分段技术特点:
- 与分页不同,分段是对程序员可见的。
- 程序员通常将程序和数据分配给不同的段:主程序、堆栈、子程序、数据等。
- 程序员必须注意最大段限制。
- 分段表中的条目包括段的基地址和限制寄存器。
- 将保护与段相关联。
分段技术的碎片化:
- 内部碎片: 无。
- 外部碎片: 没有解决,但比可变分区轻微,因为进程被分成的片段更小。
分段硬件:
- 逻辑地址翻译到物理地址需要硬件支持。
- 段表存储在内存中,包括每个段的基地址和限制寄存器。
- 段表通过段号进行索引,以查找对应的基地址和限制。
分页分段:
解决分段中的外部碎片问题:
- 一种解决方案是将分页与分段结合(例如,Intel 80x86 CPU)。
分页分段的优势:
- 减少外部碎片。Reduces external fragmentation
- 可用多个地址空间,指令可以具有较小的地址字段(不同段可以具有不同的地址空间大小)。
- 使用虚拟内存时(进程的一部分可以交换到磁盘上):
- 区分访问冲突和页面错误(页面不在内存中)。
- 可以逐步进行交换。
分页分段的劣势:
- 更为复杂。
- 每个段需要一个页面表。A page table is needed per segment.
外部碎片指的是分配给进程的内存空间中存在的、但由于空间分布不连续而不能被有效利用的未使用的小块内存。简而言之,外部碎片是内存中一些零散而无法合并的未使用空间。
在分配内存时,如果系统将可用内存分成多个不相邻的块,即使总内存足够,但由于这些块之间的隔离,可能导致一些小的、无法利用的空闲空间。这就是外部碎片的概念。
外部碎片可以导致系统难以找到足够大的内存块以满足某个进程的内存需求,即使系统的总体可用内存足够。
总结: 分段技术将逻辑内存划分为不同长度的段,对程序员可见。每个段都有自己的基地址和限制,与保护相关。虽然分段技术在内部没有碎片,但在外部可能存在碎片,这需要由程序员来管理。分段技术对于特定类型的应用程序和编程模型可能更为适用。
虚拟内存
概述:
- 虚拟内存是由系统硬件和软件支持的一种假象,即一个进程具有一个庞大且线性的可用内存空间(比主内存单元大得多)。
- 使用虚拟内存,主内存可以被视为磁盘的高速缓存(cache)。
- 在虚拟内存的上下文中,逻辑地址也被称为虚拟地址。
实际程序和虚拟内存:
实际程序通常可以分为两部分:
经常需要的部分。
很少或从不需要的部分:
处理异常错误条件的代码。
处理很少使用的选项和功能的代码。
分配超过严格需求的内存的代码(数组、表等)。
程序内的内存引用往往是聚集的(引用局部性原理)。Memory references within a program tend to be clustered.
虚拟内存的优势:
- VM通过将进程的一部分放置在主内存中,一部分放置在磁盘上,以实现更大的地址空间,从而提供了一种吸引人的方案。
- VM的核心是延迟加载。
1. 超越物理内存限制: (Programs are not limited by the physical memory space )
- 程序不受物理内存空间的限制。
- 可以根据虚拟地址空间的允许范围,使程序变得更大:
- Save funding
2. 更好的多道程序设计(Better multiprogramming):
- 可以同时执行更多进程。
- 进程可能处于ready状态(CPU利用率: 1 - p^n^)。
3. 减少I/O需求:
- 加载程序或交换程序时需要的I/O更少。
- increse CPU utilisation and throughput。
虚拟内存的特点:
- VM is Implemented by demand paging.
- Only a few pages are bring into main memory.
虚拟内存的支持:
VM system supported in hardware
- Paging mechanism.(generate page faults)
In software
- Page swapping management.
在硬件中支持虚拟内存的系统使用分页机制,当引用磁盘中的页面时生成页错误。
在软件中,需要进行页面交换管理,由操作系统的算法支持。
带有按需分页的页表:
对页表条目的添加:
存在位(Present Bit):
如果页面在主内存中,将该位设置为1。
- 当引用不在主内存中的页面时,会生成中断(页错误)。
修改位(Modified Bit):
如果页面在上次加载到主内存后已更改,将该位设置为1。
- 如果页面未更改,则在交换出去时无需写入磁盘。
控制位:
- 读/写页面(Read/Write Page): 可以由两个或多个进程共享的只读页面。
- 内核/用户页面(Kernel/User Page): 内核页面可以被强制一直保存在内存中。
按需分页的页表工作方式:
- 如果页面在内存中,页表中相应的条目包含帧号。
- 如果页面在磁盘中,页表中相应的条目包含磁盘中的地址或指向表的索引
缺页中断处理
3 major steps:
1. 服务缺页中断(service the page-fault interrput):
- 陷入到操作系统(trap to the OS)。
- 保存寄存器和进程状态(save registers and process state)。
- 检查页面引用是否合法,并确定其在磁盘上的位置。
2. 读入缺失的页面 (read in the missing page):
- 从磁盘读入缺失的页面到一个空闲帧(free frame)。
- 由于这是一个I/O操作(较慢),另一个准备好的进程被分派到CPU。
- 最终,来自磁盘的中断被发出(I/O完成)。
3. 重新启动进程:
页面加载完成后,进程可以被重新启动:
- 来自磁盘的中断表示页面已在内存中。
- 这时,进程可以切换到准备就绪状态。
- 最终,进程再次被调度,从中断处恢复执行。
缺页和性能:
将缺页保持在最低限度:
- 缺页中断会对系统性能产生重大影响
- 有效内存访问时间(T~e~)的计算方式为:
- T~e~ = p x T~f~ + (1 - p) x T~a~
- 其中:
- T~f~: 缺页中断时间(处理缺页中断的时间)
- T~a~: 内存访问时间
- p: 页面错误的概率
性能影响:
- 缺页中断时间(Tf)通常比内存访问时间(Ta)高出数个数量级(例如,10毫秒与100纳秒)。
- 因此,即使缺页的概率很低,也可能显著提高有效内存访问时间(Te)。
磁盘抖动(thrashing)和多道程序设计
磁盘抖动的问题:
- 磁盘抖动(Thrashing) 是指系统花费大量时间在页面置换上而不是执行实际工作,导致系统性能急剧下降。
- 磁盘抖动通常发生在系统试图维护过多进程时,导致它们的页面频繁地在内存和磁盘之间交换。
为避免磁盘抖动,需要采取负载控制措施(load control):
示例:
- 只执行其驻留集足够大的进程。
- 调整有效多道程序设计的程度,使缺页中断间隔的平均时间等于目标值(根据需要暂停进程)。
负载控制的目的:
- 避免系统陷入磁盘抖动状态,提高系统性能。
- 通过智能地选择执行的进程,以及动态调整多道程序设计的程度,系统可以更有效地利用资源,避免频繁的页面置换。
虚拟内存中的内存管理
在具有虚拟内存的系统中,操作系统主要处理两个内存管理问题:
1. 替换策略 (Replacement Policy):
- 当发生页面错误并且没有空闲帧可将页面换入时,操作系统必须选择一个帧进行替换(交换到磁盘上),以便将新页面带入。
- 页面替换策略通常受到一些限制:
- 操作系统内核和控制结构的大部分通常存储在锁定的帧上(不能替换)。
2. 驻留集管理 (Resident Set Management):
- 动态或静态为每个活动进程选择帧的数量。
- 允许的替换类型的选择,例如:
- 限制为导致页面错误的进程的页面。
- 包括主存储器中的任何帧。
替换策略
良好的替换策略应利用引用局部性原则:
- 引用局部性是指程序在一段时间内更有可能引用最近访问的页面。
- 如果内存引用是随机的而不是局部化的,我们将无法有效地确定工作集。
替换算法:
- Optimal (最佳):
- 替换最长时间内不会被引用的页面。(Replaces the page that will not be referenced for the longest period of time)
- 具有最小数量的页面错误,但不可能实现(需要未来事件的信息)。
- 用作衡量其他算法的标准。
Optimal算法的例子:
- Optimal算法会在每次页面错误时替换最长时间内不会被引用的页面。
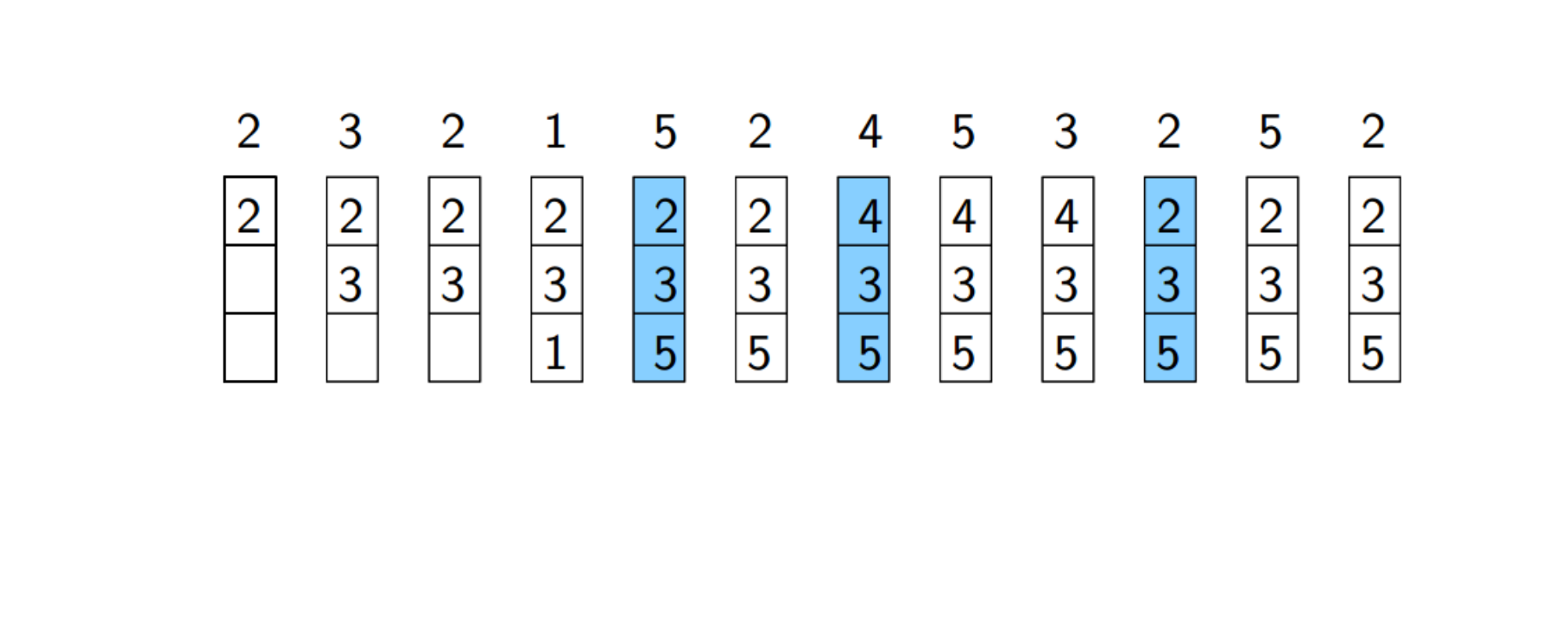
- LRU(least recently used)
- 替换长时间没被使用的页面
- 根据**(locality)**,未来一段时间这个页也不会被使用
- 较难实现,由于Time costing
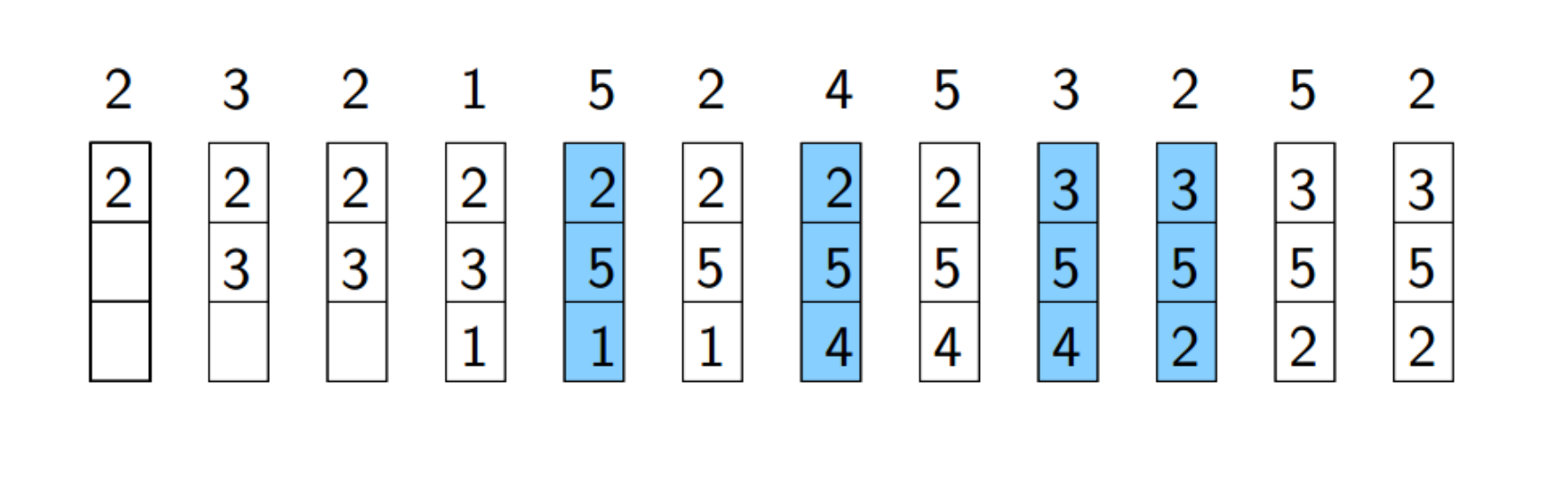
- FIFO
- 使用指针,以循环的方式替换页面
- 很久以前获得的页面可能不再使用
- 较易实现,但替换效果不好
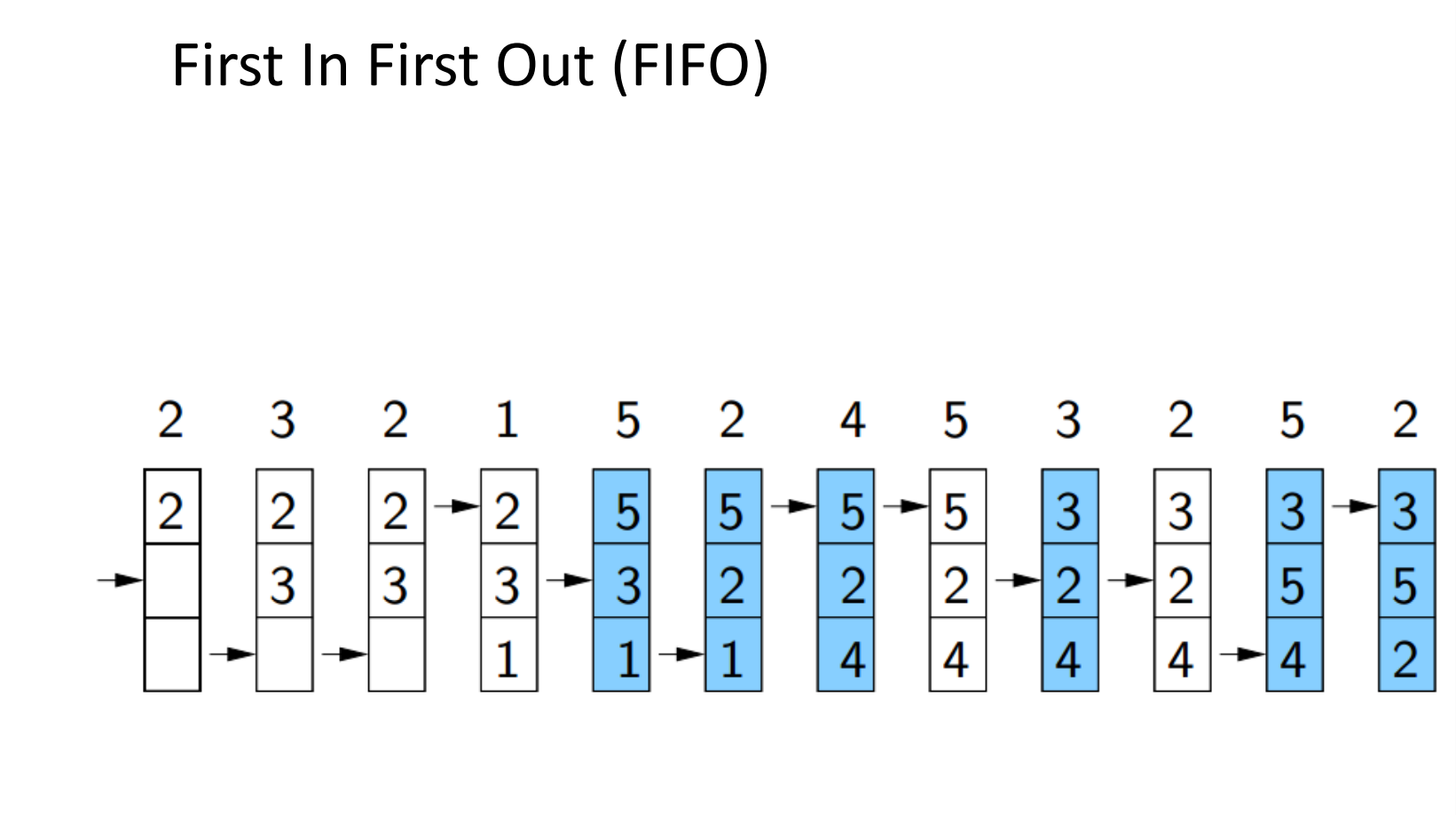
指针所指的页面被替换,同时指针移动。
若无替换页面则指针不移动。
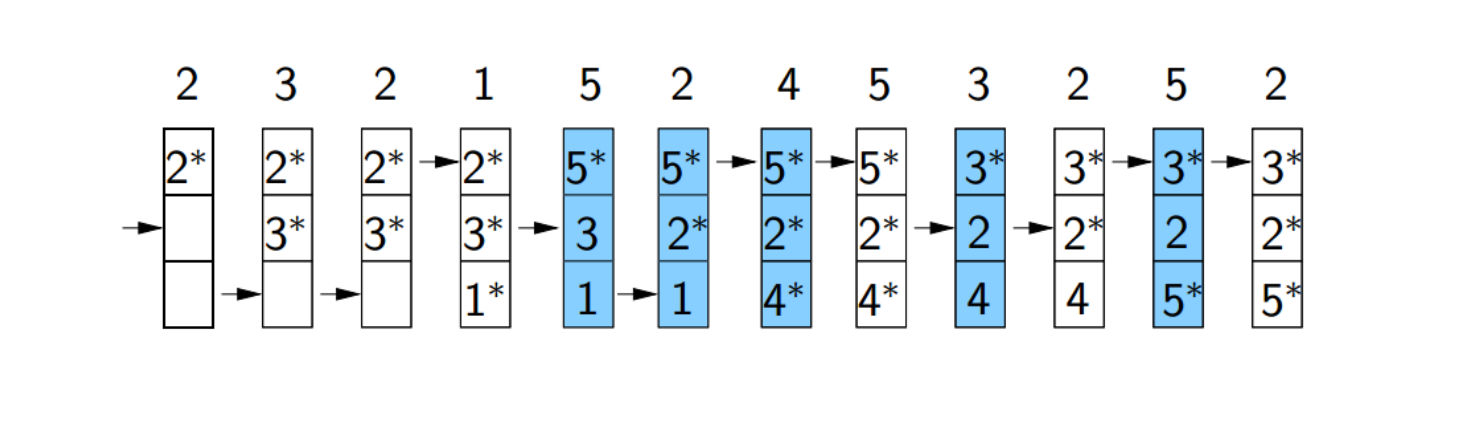
Clock policy
- FIFO的变体
算法原理:
- 初始化: 每个页面帧都有一个使用位,初始化为0。此外,有一个指向页面帧的指针,通常初始化为0。
- 页面引用: 当一个页面被引用或者首次加载到内存时,该页面的使用位被设置为1,表示它已经被访问过。
- 页面置换: 当需要进行页面置换时,操作系统开始遍历页面帧。
- 遍历过程: 遍历是一个循环过程,类似于时钟的指针在表盘上的移动。指针顺时针地遍历所有页面帧。
- 选择页面帧: 对于每个页面帧,检查其使用位。如果使用位为1,表示该页面最近被访问过,将其使用位设置为0,并移动指针到下一个页面帧。如果使用位为0,表示该页面较长时间没有被访问,选择该页面进行置换。
- 更新使用位: 在遍历的过程中,使用位为1的页面会在检查后被设置为0,以模拟它们的访问。
- 置换页面: 一旦选择了要置换的页面,操作系统将新页面加载到该页面帧中,并将其使用位设置为1。
- 继续遍历: 遍历继续,直到找到要置换的页面为止。
页面大小的选择
小页面的优势:
- Memory is better
- improve locality
大页面的优势:
- I/O transfer time is small
页表的结构
存在的问题: 页表占用大部分内存
- 2^m-n^ entries be required for m-bit long virtual address with n page offset bits.
- Ex: with m =32 and 4 KB page size -> 2^20^
Solution:
- hierarchical paging (分层页)
- inverted page table(倒页表)
分层页
Drawback: the time to convert a virtual address into a physical one is longer
倒页表
文件管理
文件管理是操作系统中的一个关键方面,涉及对计算机上存储的数据进行组织和控制。当一个进程需要存储超出其即时运行时间的信息时,它利用文件管理系统来存储和检索数据。
进程在地址空间中储存信息面临的问题:
- 易失性(Volatility)
- 当一个进程终止时,其地址空间中存储的所有数据通常都会丢失。这是因为地址空间被释放,其中存储的任何信息都不再可访问。
信息共享
进程通常需要与其他进程共享信息,特别是当它们的生命周期不重叠时。
文件管理系统提供了持久存储的机制,允许数据被写入文件并被其他进程读取,即使它们在不同的时间执行。
有限的储存大小
进程地址空间有限,将大量数据存储在地址空间内可能并不实际。
文件系统通过提供一个持久且较大的存储空间
解决:创建文件储存进程的信息
- 创建文件:
- 为了存储信息,可以为每个进程创建一个文件。文件是一种被命名的数据集合,通常保存在持久性的二级存储设备上,比如硬盘、CD/DVD、固态硬盘、磁带等。
- 文件基本操作
- 文件可以被看作是一个单元,可以执行各种基本操作,如打开(open)、关闭(close)、创建(create)、销毁(destroy)、复制(copy)、重命名(rename)、列出(list)等。这些操作使得系统能够有效地管理文件,进程可以根据需要对文件进行操作。
- 文件的单个数据操作
- 除了对整个文件的基本操作外,文件内的个别数据项也可以被操作。这包括读取(read)、写入(write)、更新(update)、插入(insert)、删除(delete)等操作。这些操作允许进程以单元的方式操作文件内的数据,从而满足不同的信息存储和检索需求。
数据层次结构(Data Hierarchy)
- 最低层级:位 (Bits)
- 位是信息的最基本单元,表示数据的最小单元,可以是0或1。
- 中等层级:固定长度的位模式
- 字节(Byte): 通常由8个位组成,是计算机中常见的存储单元。
- 字(Word): 字的长度取决于计算机体系结构,可以是8、16、32或64位。
- 字符(Character): 将字节、字或字组映射到语义符号(如ASCII码、Unicode等)的表示方式。
- 字段(Field): 字符的组合,通常表示一个特定的数据项。
- 记录(Record): 一组字段的集合,表示一个完整的数据项。
- 文件(File): 一组相关记录的集合,通常代表某种数据的完整集合。
- 最高层级:文件系统或数据库
- 文件系统: 用于组织和管理文件的系统,提供了文件和目录的层次结构,允许用户和程序访问和操作数据。
- 数据库: 一组相互关联的数据表,通过数据表之间的关系来组织和存储数据,提供了更高级别的数据管理和检索功能。
Volume
卷是一个包含文件系统的单元,这个单元通常是一个辅助储存系统。硬盘驱动器,SSD.
物理卷: 实际的硬件存储设备,如硬盘驱动器。物理卷是数据存储的物理实体。
逻辑卷: 是在物理卷上创建的文件系统或数据集的逻辑表示。逻辑卷通过文件系统的管理,将物理存储划分成可管理的单元,使用户和应用程序能够方便地访问和使用存储。
Files
文件是存储在计算机系统中的一组数据,可以包含文本、图像、程序代码等。
Record & Block 是数据的基本单元。记录可以包含各种类型的信息例如,在数据库中,记录可以是一个数据表中的一行。
- 物理记录: 是最小的可以从或写入硬件存储设备的信息单元。这是硬件层面的定义,表示实际的存储单位。
- 逻辑记录: 是在软件层面上定义的数据单元,通常包含一定数量的物理记录。逻辑记录是按照应用程序的需要进行定义的,使得处理数据更加方便和高效。
- Block: Record 通常被组织成 Block. 文件系统通常以块为单位来读取和写入数据,这有助于提高效率,减少对存储设备的访问次数。
Example in Unix & Windows
- Unix 和 Windows 文件实际上是字节的序列,在物理上分组成块。
- 字节被视为逻辑记录,而块则是物理记录。
文件特性
位置
文件储存在物理储存设备或文件系统的逻辑结构中。
- 物理位置: 文件实际存储在硬盘、固态硬盘等物理存储设备上。
- 逻辑结构: 文件系统提供了一个逻辑结构,用户和应用程序通过这个结构访问文件,而不必关心文件在物理设备上的确切位置。
大小与类型
可访问性
文件的可访问性涉及对数据施加的访问限制。
Owner Information(所有者信息): 文件通常有一个所有者,该所有者是创建或拥有文件的用户。这有助于确定文件的控制和权限。
Read / Write / Execute Status(读/写/执行状态):
文件系统通过这些状态来确定用户或进程对文件的访问权限。
- 读取(Read): 用户或进程有权读取文件的内容。
- 写入(Write): 用户或进程有权修改文件的内容。
- 执行(Execute): 仅适用于可执行文件,允许用户或进程执行文件中的程序。
设备独立性
恢复或备份功能
可选的加密功能
目录(Directories)
为了组织和快速定位文件,文件系统使用目录:
目录的定义:
- 目录是特殊的文件,其中包含其他文件的名称和位置信息。
目录项(Directory Entries):
- 目录中的每个文件都由目录项表示,目录项包含诸如文件名、位置(物理块地址或在文件系统中的逻辑位置)、大小和类型、访问、修改和创建时间等信息字段。
目录结构:
单层目录(Single-level or Flat File System):
- 这是最简单的文件系统组织形式,所有文件都存储在一个目录中。
- 不存在两个文件可以具有相同的名称。
- 文件系统必须对目录内容执行线性搜索,以定位每个文件,这可能导致性能不佳。
分层目录(Hierarchical FS):
根目录(Root Directory) 作为文件结构的起点,位于储存设备上。
嵌套结构
目录可以包含文件和其他目录,形成嵌套的结构。这意味着目录可以包含子目录,而子目录本身也可以包含文件或更多的子目录,从而形成一个层次结构。
父目录和子目录
绝对路径与相对路径
在同一目录下不能有两个文件具有相同的名称。
绝对路径:
- 绝对路径是文件名包括从根目录开始的完整路径。这样的路径提供了文件在整个文件系统中的确切位置。
- 在Unix系统中,例如:
/etc/modules/file.txt是一个绝对路径,其中/表示根目录。 - 在Windows系统中,例如:
C:\users\admin\file.txt是一个绝对路径,其中C:\是根目录。
绝对路径:
- 绝对路径是文件名包括从根目录开始的完整路径。这样的路径提供了文件在整个文件系统中的确切位置。
- 在Unix系统中,例如:
/etc/modules/file.txt是一个绝对路径,其中/表示根目录。 - 在Windows系统中,例如:
C:\users\admin\file.txt是一个绝对路径,其中C:\是根目录。
链接(Link)
- 链接的作用:
- 链接允许在文件系统中建立引用,指向其他目录或文件,促进了数据共享和访问。
- 链接的类型:
- 软链接(Soft Link): 也称为符号链接,包含文件的路径名,即逻辑名称。软链接创建一个指向目标文件或目录的符号链接,允许在文件系统中创建一个别名,而不是实际的副本。
- 硬链接(Hard Link): 包含文件在存储设备上的物理位置,通常是一个块号。硬链接创建一个指向文件数据块的额外链接,多个链接指向同一份实际数据。
- 链接与目录结构:
- 链接使我们能够将分层结构转化为:
- 非循环结构(Acyclical Structures): 允许目录具有两个不同的父目录。
- 循环结构(Cyclical Structures): 允许目录形成环,即一个目录可能是另一个目录的父目录,同时也可能是该目录的子目录。
- 链接使我们能够将分层结构转化为:
- 链接中包含的内容:
- 软链接: 包含文件的逻辑路径名。
- 硬链接: 包含文件在存储设备上的物理位置,通常是块号。
元数据(Metadata)
元数据是指文件系统本身的信息,它使得文件系统能够正常运作并保护其完整性。与用户数据不同,元数据是关于数据的数据
- 文件和目录的元数据:
- 文件名
- 文件大小
- 文件类型
- 文件创建时间、最后访问时间、最后修改时间
- 文件权限和所有者信息
- 文件所在的物理块地址或逻辑位置
- 文件系统的元数据:
- 文件系统的结构信息,如目录的组织方式,目录和文件的关系等。
- 存储空间的管理信息,包括空闲块和已分配块的跟踪。
超级块(Superblock)
文件系统创建超级块来存储关键的元数据.
超级块通常包含以下信息:
- 文件系统类型的唯一标识符:
- 用于确定文件系统的类型,例如EXT4、NTFS等。
- 根目录的位置:
- 指示文件系统中根目录的位置,从而使系统能够准确地开始检索文件和目录。
- 文件系统中块的数量:
- 描述整个文件系统的大小,以块为单位。
- 辅助设备上可用空闲块的位置:
- 记录在文件系统中哪些块是可用的,以便在需要时分配给新文件或扩展现有文件。
- 健全性检查状态、上次修改时间等:
- 用于确保超级块的完整性和文件系统的一致性。这包括上次修改超级块的时间戳以及其他状态信息。
保护与安全
保护
Protection involves controlling the access of programs,processes, or users to the resources defined by a computer system. These resources include filed, memory segments(内存段), CPU.
- 保护是实现计算机系统安全性的必要条件
保护目标
Preventing Mischievous/Intentional Violation of Access
区分资源的授权使用与非授权使用
Ensuring Consistency with OS Policies (Reliability)
子系统之间接口的错误检测。子系统是操作系统中执行特定功能的组件。通过检测接口上的错误,系统可以防止问题从一个子系统传播到另一个子系统。
计算机系统中保护的形式化模型
对象(Objects):
对象是需要访问控制的实体
hardware: CPU, memory segments, printers. software: files, semaphores.
主体(Subjects):
主体是访问对象的实体,可以是进程(processes)、用户等。主体是系统中的活动实体,它们需要执行操作并访问对象。
规则(Rules):
规则定义了主体如何访问对象的方式。例如,对于CPU,规则可以涉及执行指令;对于内存,规则可能包括读取或写入;而对于文件,规则可能包括读取、写入或执行等操作。
保护的原则
仅允许进程访问经过授权的资源:
- 这个原则确保一个进程只能访问它被明确授权的资源。
仅允许进程访问其当前任务所需的资源:需要知道原则(或最小特权原则):
- 这个原则表明一个进程只能访问它当前任务所需的资源,以限制由于故障进程导致的潜在损害。
保护域(Domain of Protection)
保护域指定了一个进程可以访问的资源。在计算机系统中,这是一种用于限定进程访问权限的概念。
<object-name, right-set> 其中:
object-name表示资源的名称,例如文件名或其他系统对象的标识。right-set是一组权限或操作集合,表示了进程对这个资源所具有的操作权限。这可以包括读、写、执行等操作。
例如,形式化定义可以表示为 D = <file F, {read, write}>,这表示保护域 D 中的任何进程都可以对文件 F 进行读取和写入的操作。
OS 保护
OS保护指的是执行管理系统资源使用规则的机制。这些规则由管理员、用户等设定,用于指导系统中各个组件对资源的使用。
一般性的机制更为可取,因为不同地方或不同时期的规则可能会发生变化。这意味着系统设计时应尽量采用通用的、不易受到特定规则变动影响的保护机制。
安全
恶意安全威胁:
- 未经授权读取数据、信息窃取,或者流量分析(属于被动威胁(passive threats),影响数据的保密性)。
- 未经授权破坏、篡改或伪造数据(属于主动威胁(active threats),影响数据的完整性或真实性)。
- 阻止系统的合法使用(属于主动威胁,影响系统的可用性)。
意外安全威胁:
- 人为错误,例如误删除文件或配置错误。
- 硬件或软件错误,例如操作系统故障或应用程序错误。
- 自然灾害,例如火灾、水灾等不可预测的自然事件。
攻击分类
强制系统调用(伪造攻击 fabrication attack)
- 尝试非法的系统调用,或者使用非法参数进行合法系统调用.
Examining memory information(机密性攻击 confidentiality attack)
- 一些系统在分配内存之前未清除相应空间,这可能导致机密信息泄漏。攻击者可能通过检查未清除的内存信息来获取敏感数据
Denial of service(availability attack)
- 拒绝服务攻击旨在通过合法但是不断闲置的指令过载计算机,使其无法执行有用的任务。这种攻击旨在削弱系统的可用性,使其难以提供正常服务。
用户认证
- User authentication is the first line of security
- 如果没有通过认证进入系统,许多攻击不可能发生
认证方式
- user knowledge (user identifier and password); most common
- user possession (key or smart card)
- user attributes (biometrics)
密码
密码作为能力(密钥):
- 将密码视为一种能力或密钥。在计算机安全术语中,密码通常是用于验证用户身份的机制,相当于一种访问权限。
密码的潜在脆弱性:
- 密码可能面临以下潜在脆弱性:
- 被猜测: 攻击者可能通过尝试不同的密码组合来猜测用户的密码。
- 被暴露或嗅探: 密码在传输或存储过程中可能被暴露或被嗅探到,导致泄露。
- 非法传输: 攻击者可能通过非法手段传输密码,例如中间人攻击(Man-in-the-Middle)。
- 密码可能面临以下潜在脆弱性:
安全的密码应该:
强大:
强密码具有足够的复杂性,使得通过暴力破解攻击变得更加困难。强密码的特征包括:
- 长度足够,以避免暴力破解攻击。
- 不常见或明显,即不与自然语言相关,以避免攻击者使用字典攻击。
定期更改: 定期更改密码可以降低密码被非法使用或拦截的可能性
*密码强度
- 长度:
- 密码长度对密码强度有显著影响。具体而言,对于长度为 n 字节的密码,可能的不同密码组合数为 2^(8n)。
- 因此,增加密码长度会显著提高密码的强度,因为攻击者需要尝试更多的可能组合。
- 频率:
- 密码的强度还受到其在使用中的频率影响。如果密码很少被使用,攻击者在尝试猜测时会面临更大的不确定性,这使密码更为强大。
- 熵:
- 熵是对密码强度的一种严格的度量。它衡量了密码中包含的信息的不确定性。
- 如果密码中包含常见词语,攻击者可以使用字典攻击,只需检查几千个常见密码,而不必尝试所有可能的组合。
密码保护措施
- 限制登录次数/频率:
- 通过限制用户登录的次数或频率,系统可以减少暴力破解攻击的风险。例如,可以实施登录失败的计数和锁定机制,以防止攻击者通过尝试多个密码来猜测正确的密码。
- 对密码文件进行访问控制:
- 限制对存储密码的文件的访问是一种基本的安全措施。然而,如果入侵者通过某种漏洞访问密码文件,这种措施就不足以提供完整的保护。
- 加密密码文件:
- 通过对密码文件进行加密,即存储加密后的密码散列(例如使用哈希函数 f(p)),可以增加密码的安全性。即使攻击者能够访问密码文件,也很难还原出原始密码。
- 但是,如果使用公共的哈希函数,攻击者仍然可能使用加密字典攻击来破解密码。
- 使用盐值(Salting):
- 为了防止加密字典攻击,可以引入盐值,即在原始密码前添加一些随机字符,再进行加密。这使得相同密码在加密后的形式也是不同的,即使密码相同,由于盐值的不同,最终的哈希值也不同。
- 盐值的使用有效地增加了攻击者进行搜索的空间,提高了破解密码的难度。