从 0 跑通 verl:在 AutoDL + RTX 5090 上复现 GSM8K PPO Quick Start 最近在学习Agentic RL 和 verl框架。为了快速上手,与其扒源码,学框架,不如把官方quick start 跑起来。
这篇文章记录在AutoDL租用的服务器上,从环境配置到跑通Qwen2.5-0.5B-Instruct + GSM8K PPO 的完整过程。
起初,我看官方文档还挺清晰的,就照着官方文档操作,谁曾想,刚解决完的报错不一会又出来另一个。遂查阅上书籍,发现不少人吐槽verl,也发现了一些经验贴。结合他们的经验,配合Codex,我顺利的跑通了。下面是一则详细的,配置/踩坑指南。
0. 租用服务器-AutoDL 配置清单
GPU:RTX 5090 32GB * 1
镜像:基础镜像 - PyTorch/2.8.0/3.12/12.8
先无卡开机配置环境,一切就绪后,再开卡。
但这里有个坑,autodl上的卡挺抢手,挺多时候会出现没有卡可用的情况。
1. 准备项目目录 学术加速
source /etc/network_turbo
1 2 3 cd /root/autodl-tmpclone https://github.com/verl-project/verl.gitcd verl
2. 创建 conda 环境 创建一个单独的 conda 环境:
1 2 3 4 5 conda create -n verl python=3.12 -y
然后安装 vLLM,同时固定 transformers 版本:
python -m pip install "vllm==0.10.2" "transformers==4.56.2"
检查一下当前环境:
python -c "import torch, vllm, platform; print('torch=', torch.__version__); print('abi=', torch.compiled_with_cxx11_abi()); print('vllm=', vllm.__version__); print('arch=', platform.machine())"
这里主要看三件事:
torch 能否正常 import; vLLM 版本是否正确; ABI 信息是否后面和 flash-attn wheel 对得上。 再次检查环境,准备手动安装flash-attn wheel
1 2 3 4 5 6 7 8 9 10 11 12 python - <<'PY' print ("python:" , sys.version)print ("python tag:" , f"cp{sys.version_info.major}{sys.version_info.minor}" )print ("torch:" , torch.__version__)print ("torch cuda:" , torch.version.cuda)print ("cxx11 abi:" , torch.compiled_with_cxx11_abi())print ("platform:" , platform.machine())
示例输出:
1 2 3 4 5 6 python: 3.12.3 | packaged by Anaconda, Inc. | (main, May 6 2024, 19:46:43) [GCC 11.2.0]
到https://github.com/Dao-AILab/flash-attention/releases/tag/v2.8.3 找到对应的版本:
flash_attn-2.8.3+cu12torch2.8cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
然后把.whl下载到服务器上,通过源码Pip构建的方式安装
1 2 3 4 cd /root/autodl-tmp/verl/3_party
切记,严格对应版本。如果 release 页面里没有和自己环境完全匹配的 wheel,不建议强行安装一个版本。更稳妥的做法是:
换一个 Python 版本,例如从 Python 3.11 / 3.12 中选择 release 支持更好的组合; 或者换一个 torch 版本,让它和已有 wheel 对齐; 最后确认 flash-attn 是否安装成功:
python -c "import flash_attn; print('flash_attn ok')"
再检查一下当前整体环境:
python -c "import torch, vllm, platform; print('torch=', torch.__version__); print('abi=', torch.compiled_with_cxx11_abi()); print('vllm=', vllm.__version__); print('arch=', platform.machine())"
3. 安装Verl 和其他依赖 安装 verl 本体:
1 2 cd /root/autodl-tmp/verl
继续安装后面会用到的依赖:
1 2 python -m pip install "trl==0.9.6" "ray[default]"
检查:
1 2 3 python -c "import trl; print('trl ok', trl.__version__)" "from trl import AutoModelForCausalLMWithValueHead; print('value head ok')" "import verl, vllm, trl, flash_attn, torch; from trl import AutoModelForCausalLMWithValueHead; print('env ok')"
如果出现:
libgomp: Invalid value for environment variable OMP_NUM_THREADS
可以执行:
export OMP_NUM_THREADS=1
4. 准备GSM8K数据集 至此,verl环境已经安装完成。开始Quick Start
verl 已经提供了 GSM8K 的预处理脚本,直接执行:
这里一定要启动网络加速,否则很慢
1 2 cd /root/autodl-tmp/verl
检查数据:
应该能看到:
1 2 train.parquet
5. 下载并缓存模型 1 python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2.5-0.5B-Instruct')"
这个步骤也要挂hf的代理
然后设置本地模型路径:
export MODEL=/root/.cache/huggingface/hub/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots/7ae557604adf67be50417f59c2c2f167def9a775
这个路径查找方式:
find /root/.cache/huggingface/hub/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots -maxdepth 1 -type d
提前下载模型,不等到训练的时候再下载。
6. 配置Wanda(可选) wandb 用来记录训练日志。
1 2 3 conda activate verl
7. 使用tumx启动训练 如果没有tumx:
1 2 apt update
检查:
tmux -V
创建一个新的 tmux session:
1 tmux new -s verl_gsm8k_ppo
进入 tmux 后,执行:
1 2 3 4 5 6 7 8 9 10 source /root/miniconda3/etc/profile.d/conda.shcd /root/autodl-tmp/verlexport MODEL=/root/.cache/huggingface/hub/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots/7ae557604adf67be50417f59c2c2f167def9a775export PYTHONUNBUFFERED=1export HYDRA_FULL_ERROR=1export OMP_NUM_THREADS=1export HF_HUB_OFFLINE=1export TRANSFORMERS_OFFLINE=1
然后启动训练:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 python3 -m verl.trainer.main_ppo \$HOME /data/gsm8k/train.parquet \$HOME /data/gsm8k/test.parquet \$MODEL \$MODEL \'["console","wandb"]' \tee -a screen.log
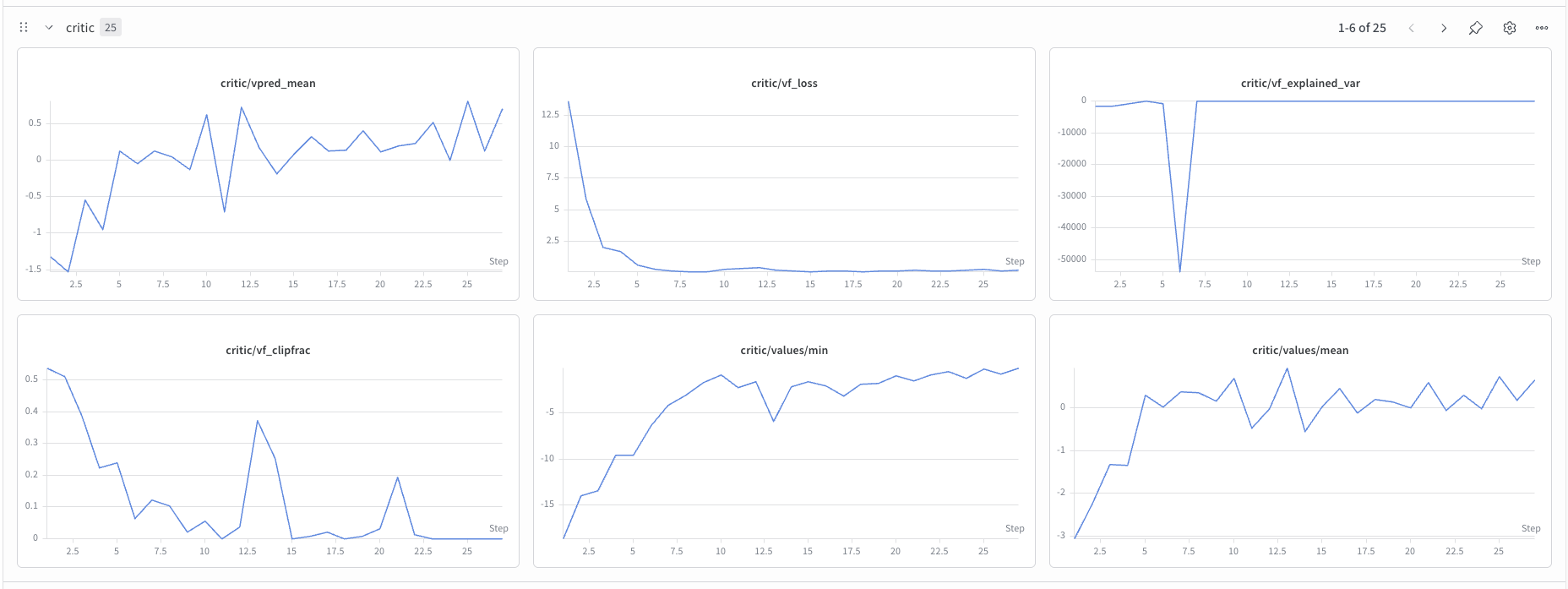
看到下方日志,说明训练正常启动:
成功训练