TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
本文最后更新于:2026年6月13日 晚上
TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
arXiv preprint, 202606
论文信息
- 论文标题:TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
- 作者:Heming Zou, Qi Wang, Yun Qu, Yuhang Jiang, Lizhou Cai, Yixiu Mao, Ru Peng, Xin Xu, Weijie Liu, Kai Yang, Saiyong Yang, Xiangyang Ji
- 机构:Tsinghua University; Tencent Hunyuan
- 发表信息:arXiv preprint, 2026
- 版本信息:arXiv v1 提交于 2026-06-09
- 论文页数:32 pages, 12 figures, 6 tables
- 主题分类:cs.LG, cs.AI, cs.CL
- DOI:10.48550/arXiv.2606.11119
- arXiv:2606.11119
TL;DR
Agentic RL 训练中,rollout 很贵,但很多 rollout 其实没用。作者提出,不要平均采样,也不要只挑 prompt,而要把 rollout 预算分配到最可能产生“成功/失败对比”的 prompt 和中间步骤上。TRACE 用一个小预测器判断哪些 prompt 或中间 prefix 最可能产生一部分成功、一部分失败,然后把 rollout 预算投入这些地方。
Abstract + Intro
RLVR 的核心痛点:不是每一条 rollout 都有用
题外话:rollout 就是一次 prompt 到模型 answer 的过程。
且如果只有最终的 reward,那么中间过程到底哪里好、哪里坏,很难察觉。这就导致 outcome-only reward 会让长轨迹上的 credit assignment 很稀疏。
为什么有些 rollout 没用
全对和全错的 rollout 都没用,有差异的才有用,方差大的才有用。
先前的方法在 prompt 层面做筛选
一种是 prompt selection,挑哪些 prompt 训练
一种是 rollout allocation,每个 prompt 分配多少条 rollout
这类的方法只在 prompt root 层面上做决策,但在 multi-turn agent 中,一条轨迹内部有很多关键节点。比如搜索任务中,模型第一步是搜一个关键词,第二步读到一个证据,第三步决定下一次搜索方向,这些中间 prefix 很可能是关键分叉点
TRACE 的核心想法
TRACE 将 ReAct 风格的每一轮:
thought, action, observation
看成 rollout tree 里的每一个节点。完整轨迹不再只是线,而是树。
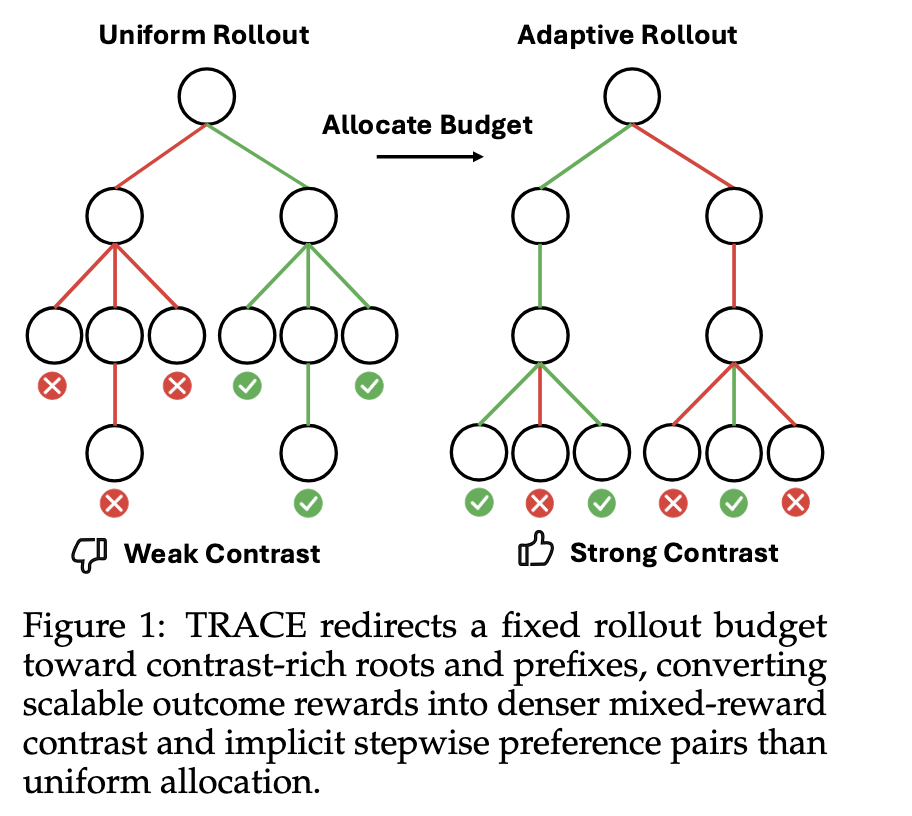
Uniform Rollout 是平均采样,可能得到弱对比;Adaptive Rollout 会把预算转移到更可能产生成功/失败混合结果的 root 和 prefix 上,从而得到更强的训练信号。
TRACE 如何判断哪个节点值得采样
训练一个 predictor,估计某个 root 或 prefix 的成功概率。
1 | |
如果预测成功率接近 0 或 1,说明这个位置大概率没什么对比:
1 | |
如果预测成功率接近 0.5,说明最可能产生混合结果:
1 | |
所以 TRACE 会更偏向在这些地方投入预算。
本文贡献
- 提出一个统一视角:prompt filtering, rollout count allocation, prefix branching,本质都是 rollout budget allocation
- 提出一个统一目标:钱应该花在最可能产生混合奖励对比的地方,也就是成功和失败都有可能发生的地方
- 实现 TRACE
Preliminaries
Multi-turn agent 的一次 rollout 如何表示
ReAct agent 的一轮
作者采用的是 ReAct 框架。每一轮 agent 会做三件事:
1 | |
也就是:
1 | |
论文把这一整轮封装成一个节点:
1 | |
History
作者定义:
1 | |
意思是:
H_t 是到第 t 轮结束为止,agent 已经看到和做过的全部历史。
其中:
1 | |
所以:
1 | |
这就是 prefix history。
模型和环境如何交替生成
- 模型根据当前历史,生成 thought 和 action
- 环境根据 action 返回 observation
训练目标
让当前 policy 生成的完整轨迹更可能成功。这里定义的奖励仍然是最终目标奖励。也就是说,奖励还是稀疏的,TRACE 后面要解决的就是 credit assignment 稀疏问题。
又有一个公式
已经走到当前 prefix H_t 之后,如果继续按照当前策略 往下采样,最终成功的概率是多少?
这是后面作者要训练 predictor 的核心,用来判断这个 prefix 还值不值得采样。
Rollout 如何变成一棵树
先生成完整轨迹,再从中间 prefix 继续分叉。
Stage 1: 先采 bare rollouts
对每个 prompt ,分配一个 root rollout count:。
这个 prompt 先采几个完整的 rollout。
Stage 2: 从中间 prefix 继续分叉
有了 bare rollout 后,每条轨迹中间有很多 prefix,TRACE 可以选择中间 prefix,重新从这里往后采样 continuation。
画个图理解一下:
1 | |
LL 视角:
- ReAct turn 视为一个节点,不总是成立。有些任务的一个 turn 中可能有很长的 thought,内部伴随多个关键决策。就像 ReAct 中的两类实验:知识密集型推理任务和决策任务。有些任务中多个 turn 才能构成完整的语义。所以是否有其他节点定义策略,ReAct 这种样式的节点定义是否是最优解,仍然值得讨论。
怎么选 rollout
在 outcome-only RLVR 中,有训练价值的不是单独的成功或失败,而是同一个 root / prefix 下面同时出现成功和失败,这样模型才能比较哪些 continuation 更好。
Rollout 不是越多越好
TRACE 追求有对比度的训练样本:
1 | |
Mixed-reward contrast construction 作为 allocation 目标
在固定的 budget 下,主动构造出“同一上下文下成功和失败并存”的样本组。
这里的“同一上下文”有两种:
第一种是同一个 prompt root:
1 | |
第二种是同一个 prefix:
1 | |
后者尤其重要,因为 prefix 共享前面的历史,差异主要来自后续 continuation,所以更接近局部 credit assignment。
LL 思考:这里也就引入了更加细致的隐式 reward。选择不同 node 对后续带来不同影响,这本身就有一点 reward shaping 的味道。
解图 Figure 2
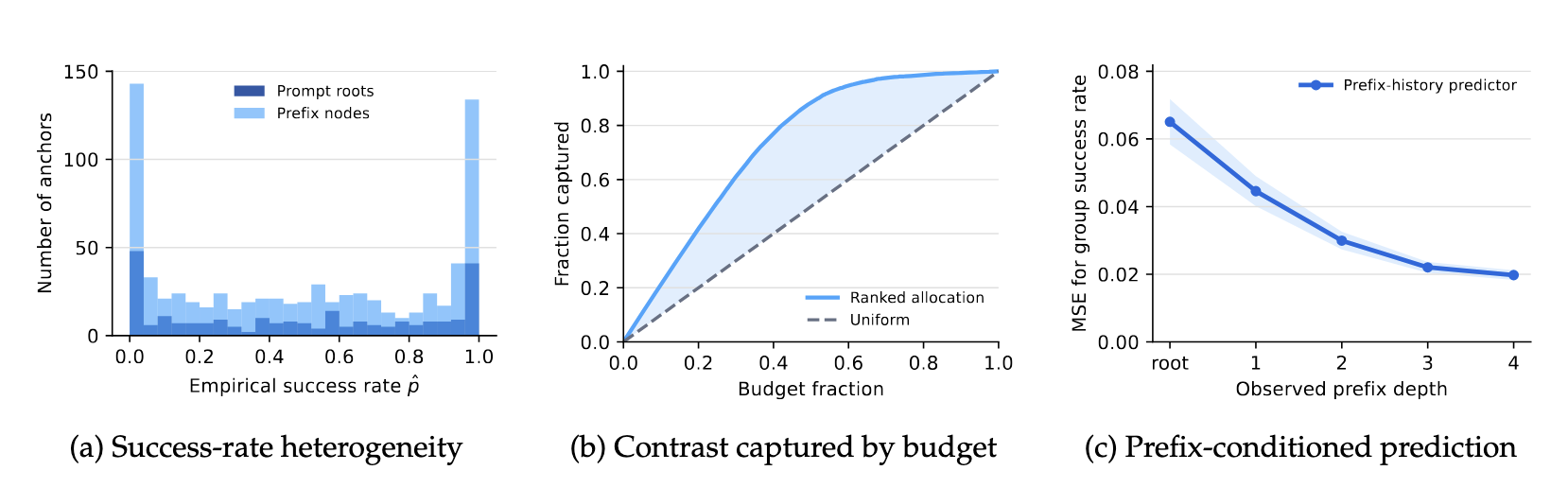
a:横轴是某个 root 或 prefix 下面采样后成功的比例。大部分 anchor 成功率接近 0 或 1。也就是说,大部分 rollout 都没有差异。
b:有用的 contrast 集中在少数 anchor 上,所以平均采样浪费预算。
c:随着 prefix 越深,predictor 预测越准。
Proposition 1: Prefix information improves group difficulty prediction
看到更多 prefix history 后,对后续成功率的预测通常会更准。
直觉显然:H_{t+1} 包含 H_t 的全部信息,还多了一轮 thought-action-observation。信息更多,理论上预测不会更差。
Proposition 2:Prefix Uncertainty as Remaining Contrast Potential
如果当前 prefix 后面已经几乎确定成功或失败,那么继续采样没多少新信息。
如果 prefix 后面成败都可能发生,那么后续不同 continuation 更可能暴露关键差异。
Proposition 3: Activation allocation dominates uniform
如果采样真的产生成功/失败混合,那么 optimizer 才会有更强的梯度信号。
没有组内 reward 差异,group-relative RL 的训练信号就会塌掉。
LL 视角:
TRACE 的 会偏好中间难度,这会不会导致忽略高价值的稀有样本?比如某个 prompt 采样 8 条,仅一条成功。那么这一条可能是一个重要且有价值的样本。
TRACE
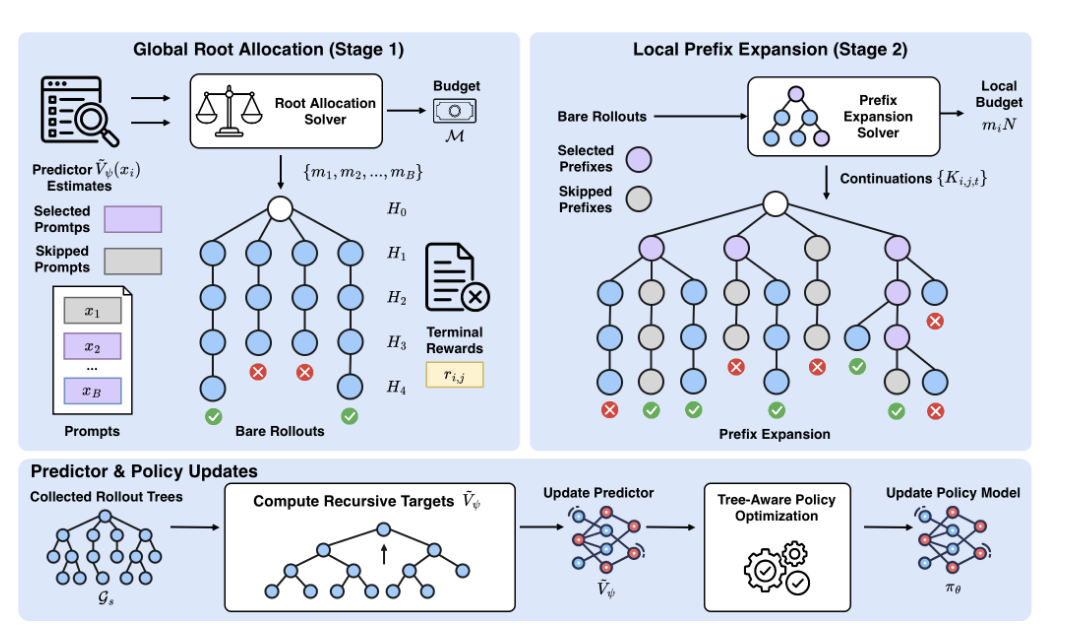
Overview
第一层是 global root allocation:
在一批候选 prompts 里,决定哪些 prompt 要采、每个 prompt 采几条 bare rollout。
第二层是 local prefix expansion:
对每个已经激活的 prompt,在它的 bare rollouts 中选择一些中间 prefix,从这些 prefix 再采 continuation。
Stage 1: Global Root Allocation
假设当前训练 step 有一个候选 prompt 池:
TRACE 会先用 predictor 给每个 prompt 估计成功概率:。
这里的 可以理解为:
当前模型从 prompt 出发,最终答对的概率。
然后 TRACE 要决定每个 prompt 分配多少条 root rollout,也就是:。
如果 ,这个 prompt 被跳过。
如果 ,这个 prompt 会生成 4 条 bare rollouts。
论文规定每个 prompt 的可选 rollout 数是:。
也就是说可以跳过,也可以至少采 2 条,但不采 1 条。原因是 group-based / tree-aware policy optimization 通常需要至少两条 rollout 才能形成比较;一条 rollout 没有组内 contrast。
TRACE 给 prompt 分配 条 rollout 的价值:
: 条 rollout 全部成功的概率
: 条 rollout 全部失败的概率
:这 条 rollout 中至少有一条成功、至少有一条失败的概率
Root allocation 优化目标
TRACE 要解这个问题:
在总 root budget M 固定的情况下,给每个 prompt 分配 ,让所有 prompt 的 之和最大。
总共只能采 条 root rollout,要把这些 rollout 分配给最有可能产生 mixed outcome 的 prompts。
Stage 2: Local Prefix Expansion
Stage 1 结束后,每个 active prompt 已经有了 条 bare rollouts,而且每条 rollout 都有一个最终 reward:。
现在 TRACE 要看这些 bare rollouts 中间的 prefix:,然后决定 。
从第 个 prompt、第 条 bare rollout、第 个 prefix 出发,额外采样几条 continuation。
是第 个 prompt 在 Stage 1 采了几条原始完整 rollout; 是每条原始 rollout 平均配多少个 continuation slots; 是具体某个 prefix 被分到几条 continuation。
对于第 个 prompt,它在 Stage 2 的总 continuation 预算是 。这些预算要在这个 prompt 下面所有可分叉 prefix 之间分配。
Prefix allocation 公式
从这个 prefix 额外采 条 continuation,至少有一条能 flips the observed reward 的概率。
flips the observed reward:
原始 bare rollout 从这个 prefix 往后走,最后有一个 reward 。
如果原始结果是成功,那么新的 continuation 只要失败,就形成 contrast。
如果原始结果是失败,那么新的 continuation 只要成功,就形成 contrast。
综上,prefix allocation 在寻找哪里最可能采到相反的 outcome。
Local prefix expansion 的优化目标
在这个 prompt 内部,把 continuation budget 分给最可能产生 opposite outcome sibling 的 prefix。
这一步之后,TRACE 就得到了一棵 rollout tree。
Predictor 怎么训练?
TRACE 需要一个 predictor:
,输入 history,预测成功的概率。
训练标签来自已经采集到的 rollout tree 中反推。
叶子节点有真实 terminal reward:
1 | |
内部节点的 target 是它下面所有 terminal descendants 的平均成功率。
比如:
1 | |
那这个 prefix 的 empirical target 就是:
1 | |
如果下面是:
1 | |
那:
1 | |
算法步骤
1 | |
LL 思考
- TRACE 极度依赖 predictor。
- predictor 的 target 来自 TRACE 自己采样的树,这会引入 bias 吗?
- local prefix budget 设置为 是否是全局最优?也许某个 prompt 内部没有什么值得分叉的 prefix,而另一个 prompt 内部有很多高价值 prefix。TRACE 当前的设计没法跨 prompt 重新分配给更好的 prefix。
实验
实验任务
Mathematical Reasoning:在 DeepScaler 上训练,模型可以调用 Python interpreter,评测 AIME24、AMC23、MATH500、MinervaMath、OlympiadBench 等数学集。
Multi-Hop QA:在 HotpotQA 上训练,agent 用本地 E5 retrieval server 检索 Wikipedia,再回答多跳问题,评测 HotpotQA、2WikiMultiHopQA、MuSiQue、Bamboogle。
Function Calling:在 BFCL v4 multi-turn split 上训练和测试,要求模型多轮调用 API,评测 base、long-context、missing-function、missing-parameter 等场景。
Baseline
ReAct:不做 RL,直接用 base model 在同样 agent scaffold 下跑。
GRPO:普通 group-based RL,prompt 随机采样,flat rollouts。
PCL:Prompt Curriculum Learning,只在 prompt 层面做 difficulty-based selection。
TreePO:有 tree rollout 和 tree-aware update,但 prefix 分叉是随机的。
TRACE:同样有 tree rollout,但 root 和 prefix 都由 predictor 指导分配。作者强调所有方法使用相同 rollout-budget accounting,所以性能差异应主要来自 allocation,而不是多采了样本。
主结果
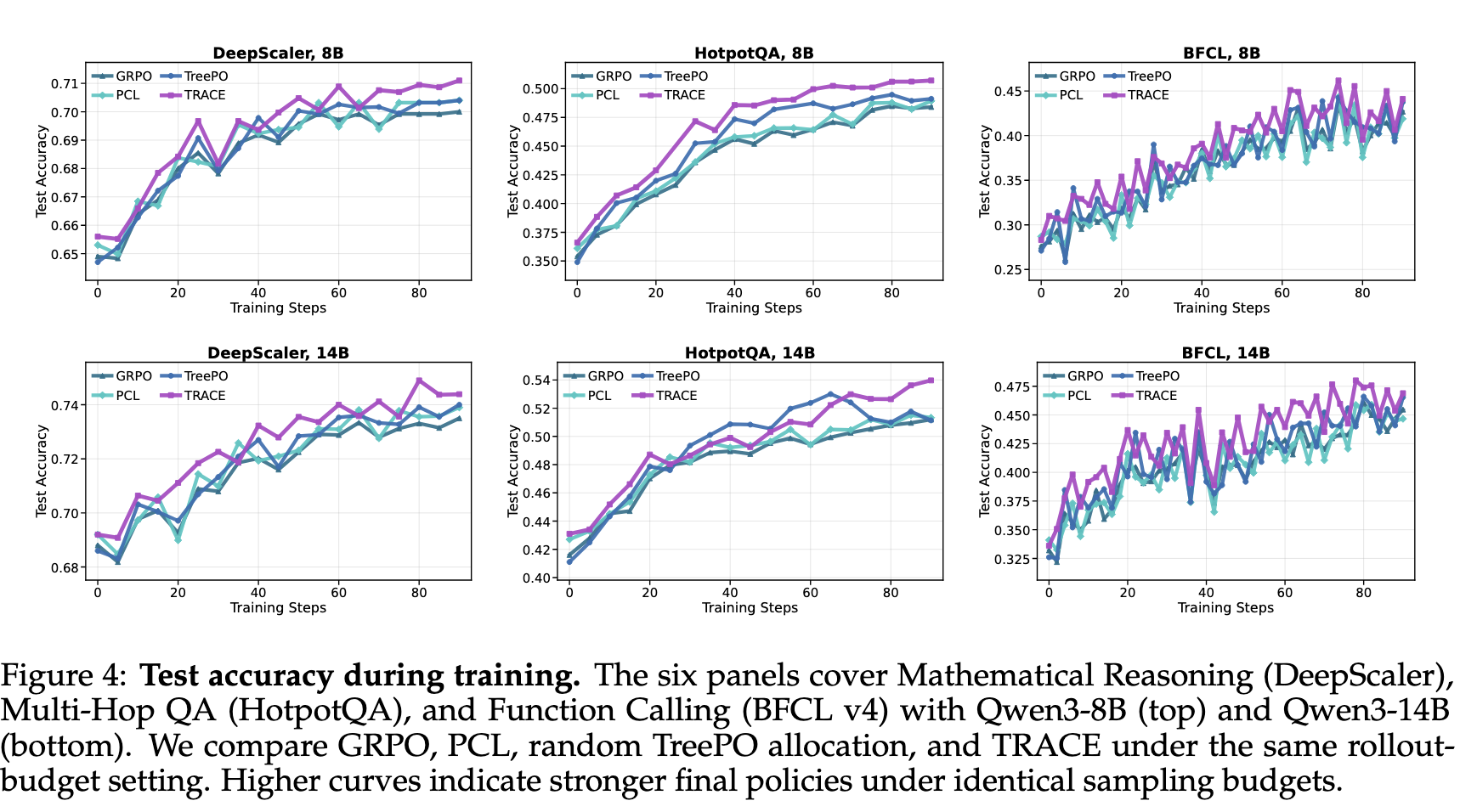
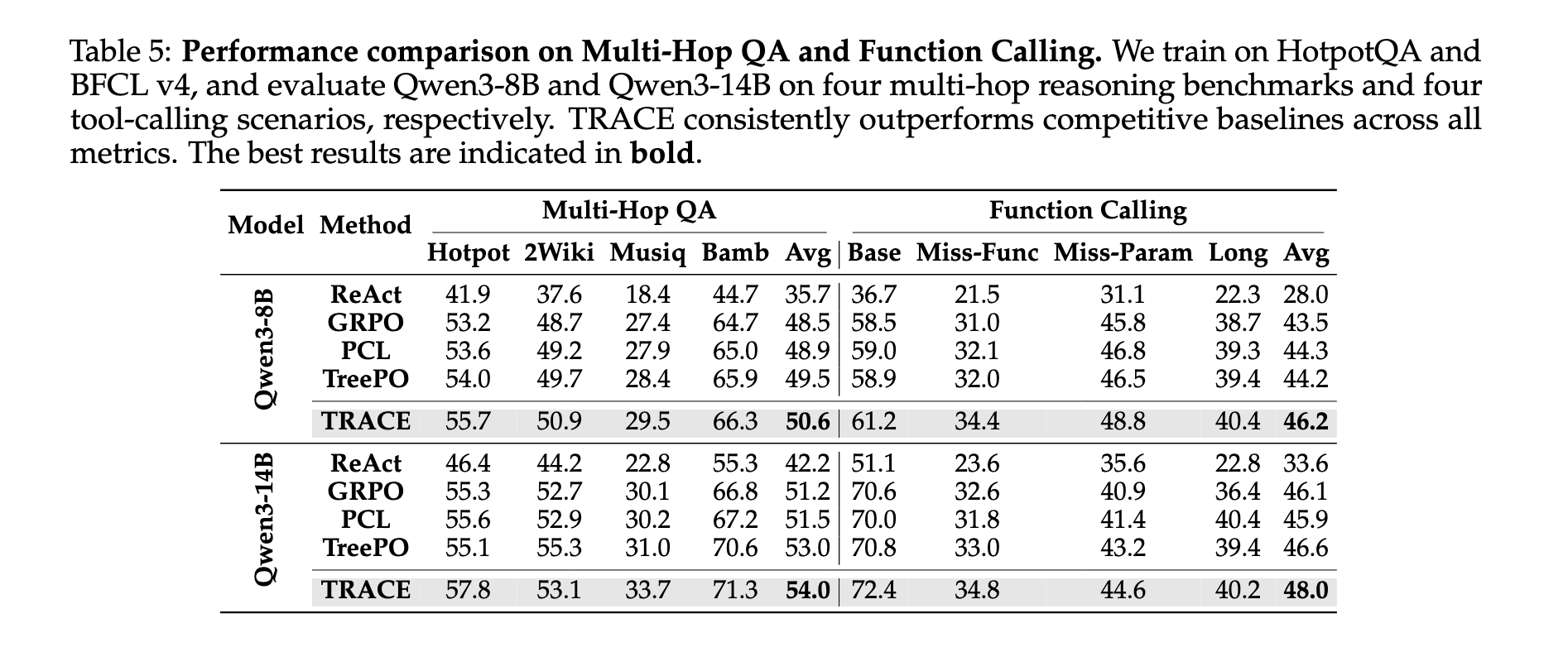
TRACE 在多数任务上有小幅提升。论文摘要中特别提到,在等采样成本下,TRACE 让 Qwen3-14B 的 Multi-Hop QA average accuracy 相比强 baseline 提升 2.8 points。
Effective Ratio 的提升
一个 batch 里,有多少 prompt 的 rollout tree 同时包含成功和失败 terminal leaves。
这个提升是显著的,同时我认为也是显然的。这是 TRACE 中间的选择偏好。
LL 思考
- effective ratio 提升很大,但最终效果多数只是 1-2 个点量级。机制上还需要进一步分析:更高的 contrast ratio 是否一定能稳定转化为 policy improvement?
- predictor 要是失效了,TRACE 会有多大程度的下降,这是需要验证的。
- 作者提到 prefix examples 只占 predictor 预测样本的 6%。为什么是 6%,这个参数变动会导致什么?这是经验选择,还是有更系统的依据?
总结
TRACE 的核心价值不是提出一个新的 RL optimizer,而是把 rollout collection 这件事重新建模成 budget allocation:prompt root 要不要采、采几条;中间 prefix 要不要继续分叉、分几条。它瞄准的是 RLVR 中很实际的问题:不是 rollout 数量不够,而是很多 rollout 没有产生可比较的 reward contrast。
我觉得这篇文章最值得关注的点是 prefix-level allocation。它把 agent 轨迹里的中间历史当成可重新分配采样预算的 anchor,让 outcome-only reward 在树结构里产生更多局部对比。Limitation也存在:TRACE 的收益高度依赖 predictor 的校准质量,而且当前 prefix budget 仍然是在单个 prompt 内部分配,未必是全局最优。