RAGEN: LLM Agent也能通过强化学习学会“思考”和“自我进化”吗?
本文最后更新于:2026年6月17日 晚上
RAGEN: LLM Agent也能通过强化学习学会“思考”和“自我进化”吗?
arXiv preprint, 2025
论文信息
- 论文标题:RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
- 作者:Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, Manling Li
- 机构:Northwestern University; University of Washington; Stanford University; Microsoft; New York University; University of British Columbia; Singapore Management University
- 发表信息:arXiv preprint, 2025
- 版本信息:arXiv v1 提交于 2025-04-24,v2 修订于 2025-05-26
- 论文页数:39 pages
- 主题分类:cs.LG, cs.AI, cs.CL
- DOI:10.48550/arXiv.2504.20073
- arXiv:2504.20073
- Code / Environments
- Project Website
TL;DR
RAGEN 发现,多轮 Agent RL 不是简单把 PPO/GRPO 搬到环境里就能成功。模型前期会进步,但很容易陷入 Echo Trap:轨迹奖励方差下降、输出模板化、梯度爆炸,最后性能崩溃。 更关键的是,仅靠最终任务奖励,<think> 不会自然变成真实推理,反而可能退化为伪推理。
Overview
RQ: LLM Agent 是否可以通过多轮强化学习,在和环境交互的过程中自己变强?如果能,如何训练?如果不能,为什么失败?
本文提出:
StarPO: 用于多轮Agent RL的训练框架
RAGEN: 基于StarPO的Agent训练和评估系统
Agent RL为什么比RLHF/GRPO难
- Long-horizon decision making
- 环境反馈随机性
- 奖励分配难。最后成功,哪一步优异哪一步有害。
作者在Intro中给出需要探寻的问题
哪些设计因素可以让RL在Agent训练上更稳定,更有效
StarPO
State-Thinking-Actions-Reward Policy Optimization
1 | |
从单个回答的优化,扩展到,整段Agent交互轨迹的优化
RAGEN的评估环境
| 环境 | 类型 | 测什么能力 |
|---|---|---|
| Bandit | single-turn, stochastic | 风险选择、符号推理 |
| Sokoban 推箱子 | multi-turn, deterministic | 多步规划、不可逆操作 |
| Frozen Lake | multi-turn, stochastic | 随机环境中的规划 |
| WebShop | multi-turn, open-domain | 真实网页购物任务、语言理解 |
本文发现
- 多轮Agent RL会出现Echo Trap
模型在RL训练中逐渐陷入某种重复、模版化、局部有效的行为模式,看起来在推理,但其实只在重复曾经拿到reward的套路。三种表现:
| 指标 | 直觉含义 |
|---|---|
| reward variability collapse | 不同 rollout 的奖励差异变小,模型行为越来越单一 |
| entropy drop | 输出越来越确定,不探索了 |
| gradient spikes | 梯度突然变大,训练不稳定甚至崩掉 |
解决:提出StarPO-S,稳定版框架
- rollout 的设计会影响self-evolution
RL中, 模型自己生成的rollout就是训练材料。如果rollout不好,模型用错误经验继续学习,最后越学越偏。
作者强调三个稳定训练的设计方案:
| 设计 | 直觉解释 |
|---|---|
| 初始状态要多样 | 不要总在类似题目上训练,否则容易过拟合 |
| 交互粒度要适中 | 每轮动作不能太少,也不能太长 |
| rollout 要频繁更新 | 用当前模型生成当前数据,减少 policy-data mismatch |
- 没有细粒度reward, reasoning不会自然出现
即使强制模型输出
<think>...</think>,也不代表它真的在推理。
如果reward只看最终是否成功,模型可能学到:
1 | |
Framework
MDP公式化
当前模型看到状态s_t和之前发生过的历史动作,产生新的动作a_t
环境看到这个动作后,返回奖励r_t和新状态
StarPO: 轨迹级优化
State-Thinking-Action-Reward Policy Optimization
这是一个通用RL框架,优化整条轨迹
模型在环境M中生成一整条轨迹**** ,然后根据整条轨迹的总奖励来更新模型。
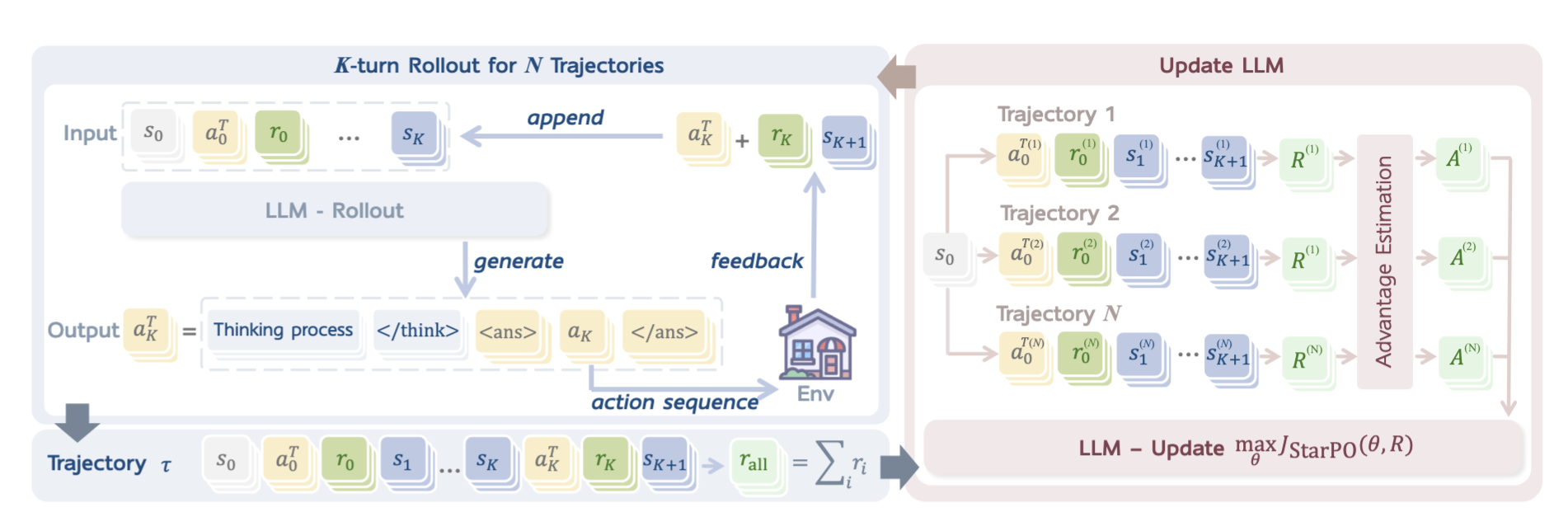
1 | |
RAGEN System
环境接口 + rollout 生成 + reward 分配 + PPO/GRPO 更新 + 稳定性监控
实验
环境一:Bandit
模型能不能在有噪声反馈下,学会选择长期期望收益更高的选项。
1 | |
1 | |
如果模型只看短期反馈,它可能觉得 Phoenix 更好,因为 Phoenix 经常给正奖励。 但如果模型理解期望收益,它应该慢慢学会 Dragon 更值得选。
所以 Bandit 测的是:
1 | |
奖励函数
每次选择的奖励就是模型奖励函数
环境二:Sokoban 推箱子
Agent 要在网格里移动,把箱子推到目标位置。
1 | |
奖励函数
+1:每个箱子在目标点上 -1:箱子不在目标点上 +10:任务完成 -0.1:每执行一个动作
环境三:Frozen Lake
Agent 要从起点走到目标点,同时避开洞。环境可能随机滑到别的方向。
1 | |
奖励函数
成功到达目标:+1 其他情况:0
环境四:WebShop
WebShop 是一个网页购物任务。Agent 收到用户需求,然后要搜索、点击、阅读商品信息,最后买到符合条件的商品。
最真实的应用场景
训练设置
前三个环境用Qwen-2.5 Instruct 0.5B
webShop用Qwen-2.5 Instruct 3B
每个 batch 采样 P = 8 个 prompts 每个 prompt 生成 N = 16 条 rollouts 最多 5 turns 最多 10 actions
评估指标
success rate
Rollout entropy: 模型还在探索吗?
高 entropy:
1 | |
低 entropy:
1 | |
适度下降是正常的,因为训练后模型应该更有把握。 但如果 entropy 下降太快,就可能说明模型过早变成模板化输出。
in-group reward variability:同一题的多次尝试是否有差异?
假设同一个 prompt 生成 16 条 rollouts:
1 | |
说明模型在尝试不同策略,有好有坏,有学习信号。
但如果变成:
1 | |
或者:
1 | |
方差就很低。
低方差意味着:
1 | |
response length:推理是否在变短?
如果训练过程中 response length 越来越短,可能说明:
1 | |
gradient norm:训练是否稳定?
如果 gradient norm 平稳,说明训练相对稳定。 如果突然 spike,说明模型更新很剧烈,可能要崩。
Findings
- 单轮RL无法直接适配到多轮RL
- Agentic RL中的训练崩塌体现为Echo Trap
- collapse可以提前预警
- 过滤低方差轨迹提升稳定性和效率
- 任务多样性,适中的动作长度,rollout频率影响rollout质量
- 如果没有细致的奖励设计,推理就不会出现
1.单轮 RL 不能直接搬到多轮 Agent RL
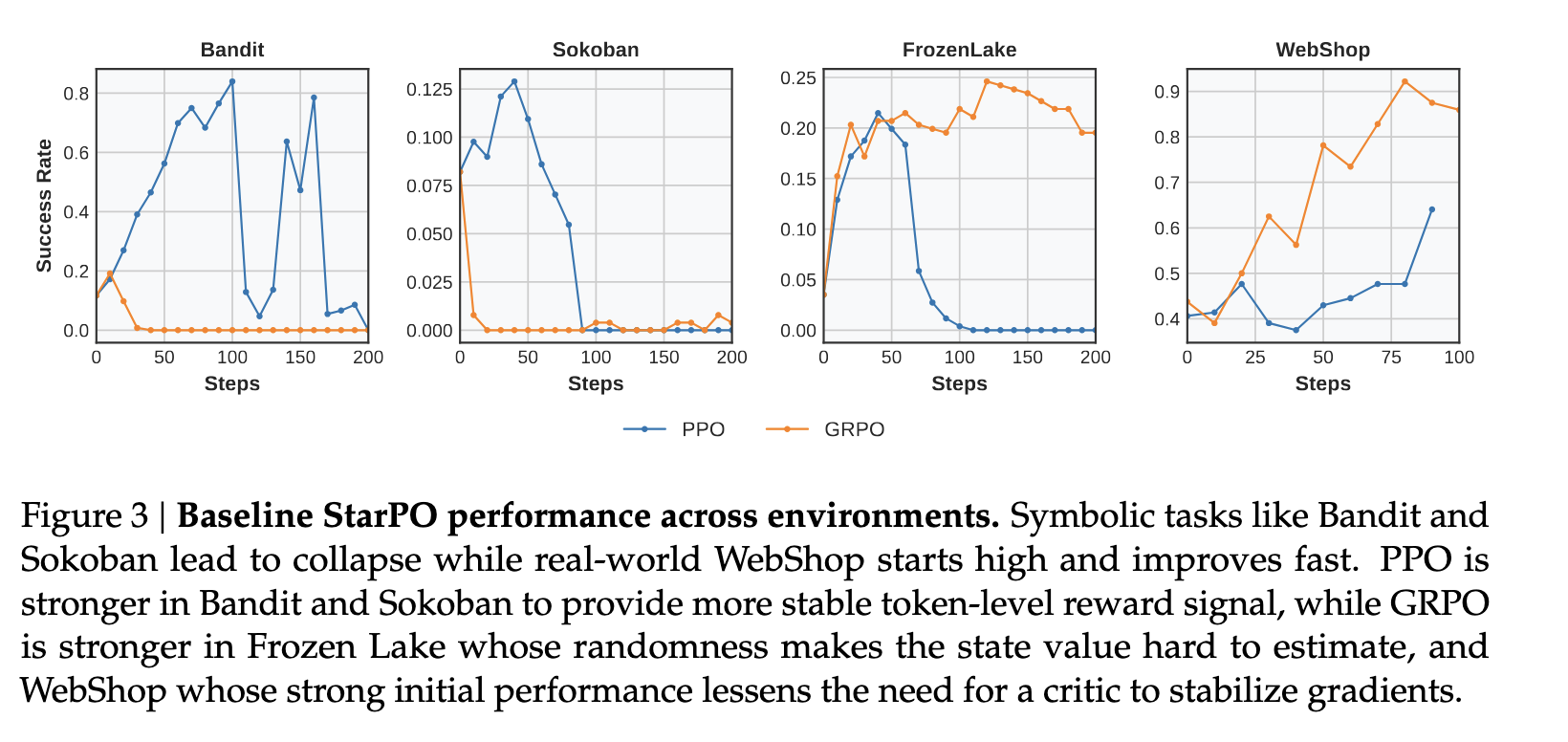
指标呈现先升高,然后突然下降的趋势,然后崩溃。
1 | |
2. Agentic RL中的训练崩塌体现为Echo Trap
模型在RL训练中逐渐陷入某种重复、模版化、局部有效的行为模式,看起来在推理,但其实只在重复曾经拿到reward的套路。三种表现:
| 指标 | 含义 |
|---|---|
| reward variability collapse | 不同 rollout 的奖励差异变小,模型行为越来越单一 |
| entropy drop | 输出越来越确定,不探索了 |
| gradient spikes | 梯度突然变大,训练不稳定甚至崩掉 |
3. collapse可以提前预警
如何发现collapse
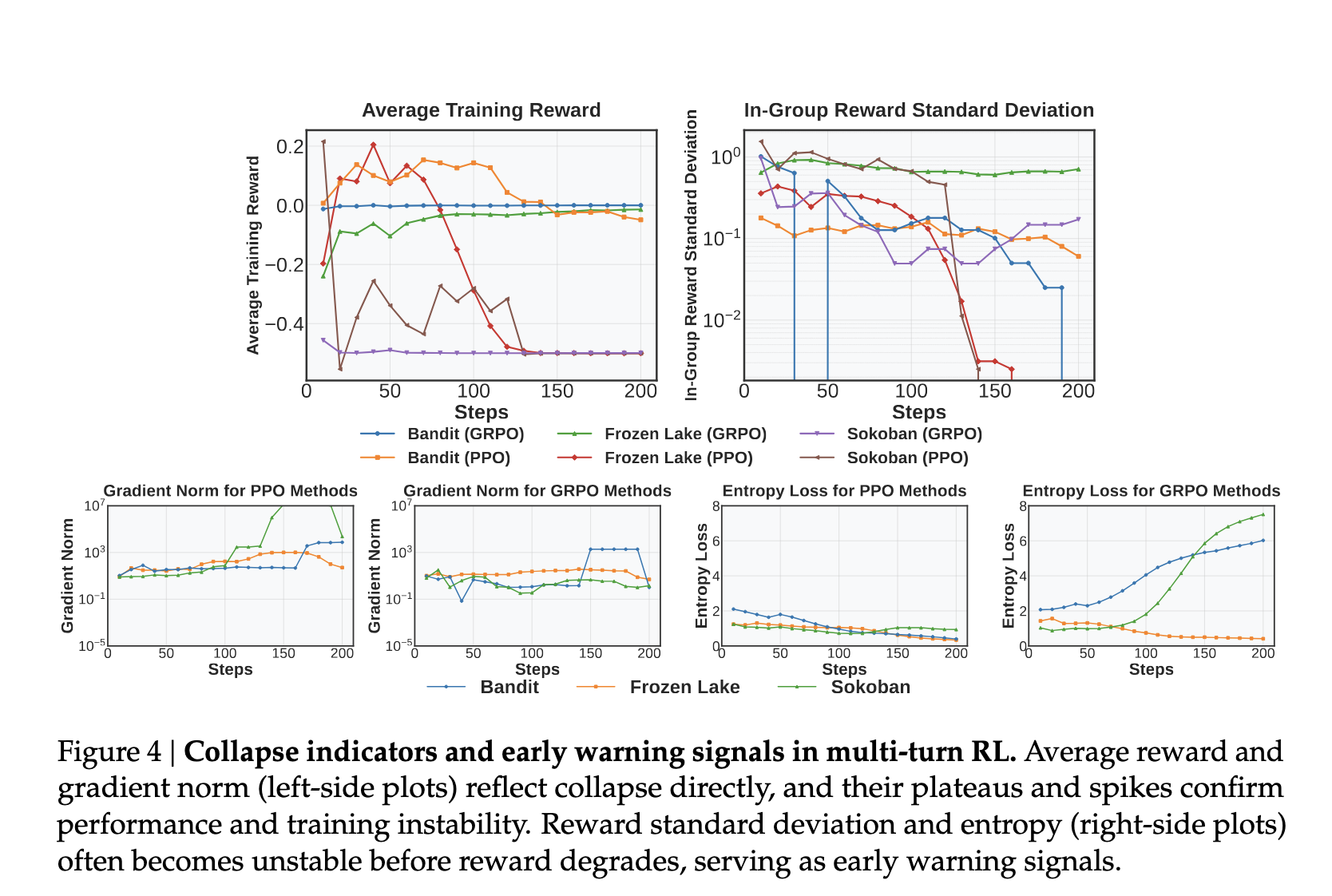
Average Reward
奖励不再上升或快速下降,说明模型的任务表现不再提升,甚至退化。
这是最直观的collapse表现。
In-Group Reward Standard Deviation
同一个 prompt 下,多条 rollout 的 reward 差异有多大。
当这个指标下降时,意味:
探索减少,行为趋同
Gradient Norm
一旦梯度突然爆,后面很难恢复。
Entropy
Entropy 低,说明模型越来越确定地输出某些 token。
训练过程中 entropy 缓慢下降是正常的,因为模型学会了更优策略。
但如果 entropy 下降过快或变化异常,就说明:
1 | |
4. 过滤低方差轨迹提升稳定性和效率
基于Finding3, 作者提出StarPO-S,目标是解决sampling quality, gradient stability, exploration regularization
StarPO-S中的三个设计:
- Uncertainty-based filtering:只训练“有信息量”的样本
更多的训练模型还不确定的任务,过滤低方差的轨迹。
这与 Active Learning 的原则相一致,即不确定性较高的示例能提供最具信息量的学习信号。
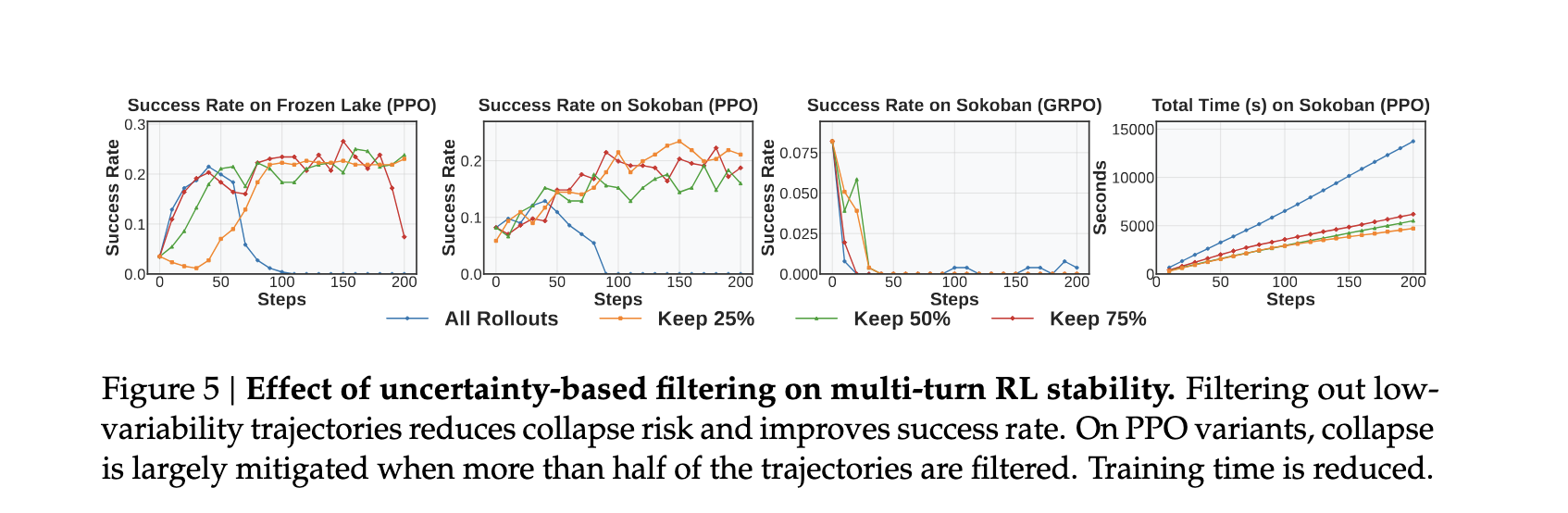
左侧两个图可以看出,在PPO算法下,filtering low-variability rollouts 的操作推迟了训练中 collapse的发生。
GRPO 的的效果就没那么好,可能是因为 critic-free 的设计。
- KL 移除
尝试移除KL约束,不限制模型探索,让模型自由的向更高reward探索。
但也有风险,模型可能跑偏
- Clip-Higher
非对称裁剪。对高reward行为,允许模型更积极的提高概率。
5. 任务多样性,适中的动作长度,rollout频率影响rollout质量
trajectory 质量很重要
三个rollout维度分析:
- Task Diversity: 任务初始状态多样性
每次 rollout-update cycle 中,使用多少个不同的 prompt / 初始状态。
- Interaction Granularity,每轮动作数要适中
增加 action 有助于 planning, 但过长的 rollouts 可能引入噪音。

实验发现 5 - 6 个action 效果最好。
- Rollout Frequency,rollout 要足够新
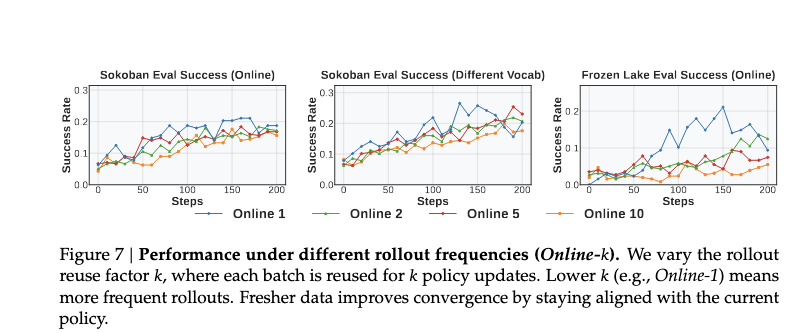
6. 如果没有细致的奖励设计,推理就不会出现
在简单单轮任务里,reasoning 有帮助;但在多轮任务里,如果 reward 只看最终结果,reasoning 会逐渐消失,甚至变成伪推理。
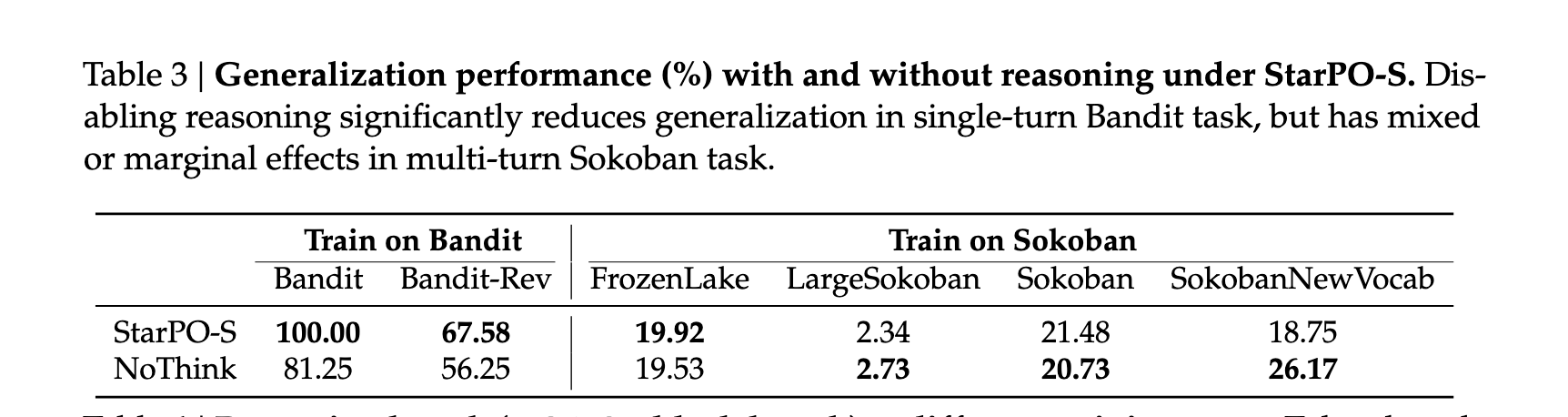
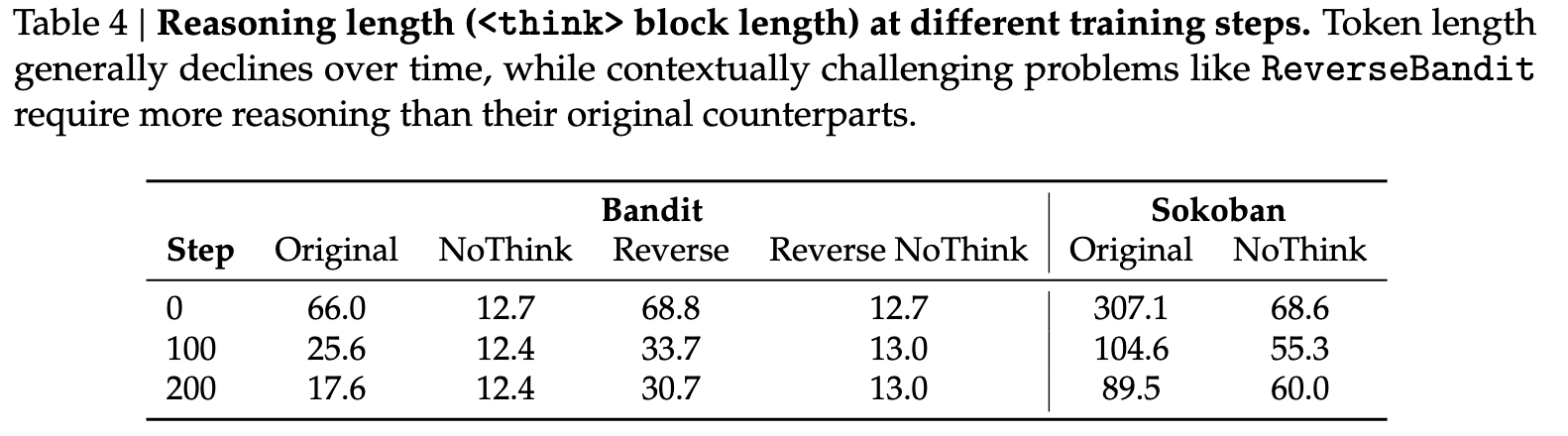
reasoning在多轮任务中越来越短
为什么reasoning消失?
多轮任务中的 reward 通常是 sparse 和 delayed,它无法区分“真正有用的推理”和“碰巧成功的试错”。
问题根源出在,reasoning和actions没有对齐,模型的rollout中可能出现答案是对的,但是reason是错的情况
所以需要 fine-grained, reasoning-aware reward design。
这里带来的挑战是:当奖励本身无法反映推理的质量时,我们该如何持续强化有用的推理。