RAGEN-2: 模型还在认真胡说,但已经不看题了
本文最后更新于:2026年6月18日 下午
RAGEN-2: Reasoning Collapse in Agentic RL
arXiv preprint, 2026
论文信息
- 论文标题:RAGEN-2: Reasoning Collapse in Agentic RL
- 作者:Zihan Wang, Chi Gui, Xing Jin, Qineng Wang, Licheng Liu, Kangrui Wang, Shiqi Chen, Linjie Li, Zhengyuan Yang, Pingyue Zhang, Yiping Lu, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, Manling Li
- 机构:Northwestern University; MLL Lab et al.
- 发表信息:arXiv preprint, 2026
- 版本信息:arXiv v1 提交于 2026-04-07
- DOI:10.48550/arXiv.2604.06268
- arXiv:2604.06268
TL;DR
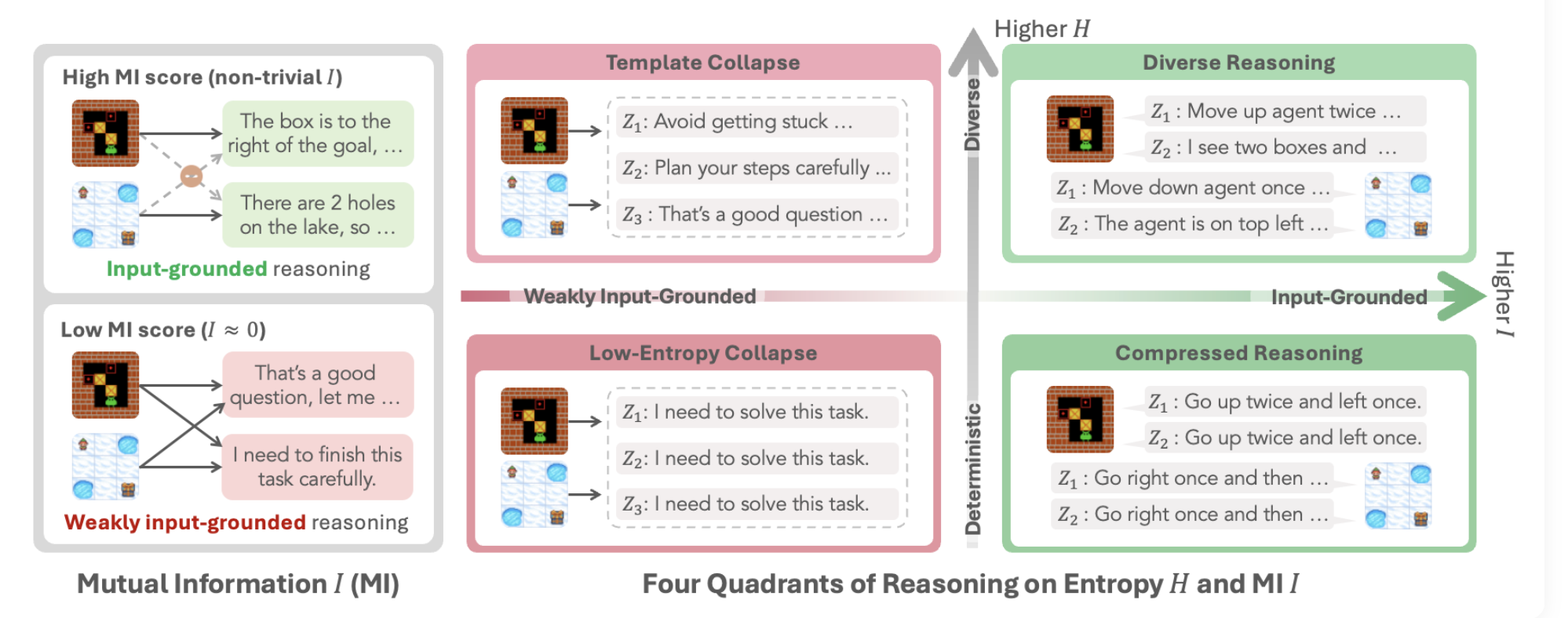
RAGEN-2 发现,Agentic RL 中会出现一种更隐蔽的推理崩塌:模型的 reasoning 表面上仍然多样,entropy 也没有明显下降,但不同输入下的 reasoning 正在变成相似模板,不再对输入内容敏感。作者把这种现象称为 template collapse。
传统 entropy 只能衡量同一输入下输出是否多样,无法判断 reasoning 是否真的携带输入信息。因此,RAGEN-2 引入 mutual information proxy 来检测 reasoning 与输入之间的依赖关系,并用 reward variance 解释这种 collapse 的来源:低 reward variance 会导致 task gradient 变弱,而 KL / entropy regularization 这类输入无关项相对占主导,最终抹掉跨输入差异。
解决方案是 SNR-Aware Filtering:每轮训练时优先保留 reward variance 高的 prompts,让 policy update 更多来自高信号样本。
Overview
研究背景
多轮 LLM agent 的 RL 训练本身不稳定。模型在环境中边推理边行动,reasoning 质量会直接影响 action 选择,action 又会影响后续 observation 和最终 reward。如果 reasoning 逐渐偏离输入,整条轨迹都会被带偏。
以往大家常用 entropy 监控训练过程:
- entropy 高:说明输出仍然有多样性,没有完全模式坍塌;
- entropy 低:说明模型越来越确定,探索空间可能被压缩。
RAGEN-2 的关键观点是:entropy 只回答了同一个输入下,模型输出是不是多样;它没有回答不同输入下,reasoning 有没有真的跟着输入变化。
假设有两个输入:
- 输入 A:帮我找红色、30 美元以下的衬衫;
- 输入 B:帮我找蓝色、100 美元以下的耳机。
有效的 agent reasoning 应该明显不同:
- A 的 reasoning 应该关注
red shirt和price under 30; - B 的 reasoning 应该关注
blue headphones和price under 100。
但 template collapse 的模型可能总是输出类似内容:
I need to carefully analyze the user request, search for relevant options, compare attributes, and choose the best item.
这句话看起来合理,也可以换很多种说法,所以 entropy 可能不低。但它没有真正响应输入差异。
Template Collapse 是什么
Template collapse 指模型的 reasoning 看起来仍然流畅、多样,但不同输入下的 reasoning 逐渐变成相似模板,不再携带足够的输入信息。
普通 low-entropy collapse 是:
模型总是输出完全一样的话。
Template collapse 更隐蔽:
模型看起来每次说法不一样,但背后的 reasoning 骨架差不多,而且和输入关系不强。
因此,reward 和 entropy 都可能看起来没问题,但 reasoning 已经悄悄坏了。
本文关注的三个问题
How to diagnose?
作者提出 mutual information proxy:如果只看到模型的 reasoning,能不能猜出它对应哪个输入?如果能猜出,说明 reasoning 和输入强相关,MI 高;如果不能,说明 reasoning 太模板化,MI 低。
Why does it happen?
作者用 signal-to-noise ratio, SNR, 解释 template collapse。在 RL 训练中,真正有用的是 task signal:哪些 trajectory 得分高,哪些得分低,由此指导模型更新。
如果同一个 prompt 下采样出的多条 trajectory reward 都差不多,那么 reward variance 很低,advantage 差异也很弱。模型就很难知道到底哪种 reasoning 更应该被强化。这时 KL regularization、entropy regularization 这些输入无关项反而会相对占主导,逐渐抹掉不同输入之间的 reasoning 差异。
简单说:
奖励方差低 -> 任务梯度弱 -> 正则项/噪声主导 -> reasoning 变得输入无关 -> template collapse
How to address it?
既然问题来自低 SNR,那么解决方案就是:每轮训练时,优先保留 reward variance 高的 prompts。
同一个 prompt 下,如果不同 trajectory 的 reward 差异明显,说明这个 prompt 能提供有效训练信号:
- 哪些 reasoning/action 更好;
- 哪些 reasoning/action 更差;
- advantage 更有区分度;
- policy gradient 更可能朝任务相关方向更新。
本文贡献
发现并定义 template collapse
模型 reasoning 在同一输入下可能仍然多样,但跨输入不再有区分度。作者用 MI proxy 检测这种现象。
用 SNR 解释 template collapse
低 reward variance 让 task gradient 变弱,而 KL / entropy regularization 仍然存在,于是输入无关的更新成分占主导。
提出 SNR-Aware Filtering
训练时按 reward variance 过滤 prompt,只用高信号 prompt 更新模型,从而提升 reasoning 的 input dependence 和任务表现。
How to Identify Template Collapse
变量定义
表示模型在某一轮生成 reasoning 之前能看到的全部上下文,包括 system prompt、历史 observations、历史 actions、历史 reasoning。
表示这一轮模型生成的 reasoning token sequence,不包括 action tokens 和边界标记。
为什么 Entropy 不够
在此之前,常见经验做法是:将熵作为过程稳定性的指标,将奖励作为结果稳定性的指标。RAGEN-2 发现,稳定的熵不等于稳定的推理。
作者引入一个信息论分解:
表示模型整体输出 reasoning 的多样性:
- 高:模型能输出很多不同的 reasoning;
- 低:模型总是输出一样的 reasoning。
但这个粒度太粗,因为它混合了两个来源:
- 同一个输入下的随机性;
- 不同输入导致的差异。
:同一输入下的多样性
表示给定同一个输入 时,reasoning 还有多少变化。这是传统 entropy-based 指标能识别的内容。
比如同一道数学题,模型可以这样想:
- 方法 A:代数变形;
- 方法 B:枚举验证;
- 方法 C:画图直觉。
这说明 高。但是,这还不能说明模型真的理解不同输入。
:输入与推理之间的互信息
表示输入 和 reasoning 之间的 mutual information。
直觉上:
看到 reasoning ,是否可以推断它来自哪一个 ?
如果能,说明 reasoning 对输入敏感, 高;如果不能,说明 reasoning 太模板化, 低。
高 MI reasoning:
The target is 24 and numbers are 3, 8, 8, 1. Since 8 x 3 = 24, I can use the remaining numbers in a neutral way if allowed…
一看就知道它和 Countdown 里的具体数字有关。
低 MI reasoning:
I need to carefully analyze the problem, identify constraints, try possible operations, and provide the final answer.
这句话对任何数学题都能用。它很流畅,但没有输入信息。
Template Collapse 的正式定义
Template collapse 可以写成:
也就是说:同一个输入下 reasoning 仍然看起来多样,但不同输入之间已经没有足够的区分度。
Mutual Information Proxy
Mutual information 在 LLM token sequence 上很难直接计算,因为 和 都是高维文本序列,分布也不可解析。
作者提出 empirical proxy。核心想法很直观:
如果 reasoning 真的是输入驱动的,那么把它拿去和一批 prompts 匹配时,它应该最像自己的原始 prompt。如果 reasoning 是模板化的,那么它和哪个 prompt 搭配都差不多。
In-Batch Cross-Scoring
假设一个 batch 里有:
- 个 prompts;
- 每个 prompt 采样 条 reasoning。
第 个 prompt 是 ,它生成的第 条 reasoning 是 。
然后,把每条 reasoning 放到所有 prompt 下打分,形成一个 scoring matrix:
这个分数的含义是:
第 个 prompt 生成的第 条 reasoning,在第 个 prompt 条件下有多合理?
如果 reasoning 真的和输入 强相关,那么 应该最大,也就是它应该最匹配自己的 prompt。
经过长度归一化后,可以得到两个值。
Matched:原始 Prompt 下的匹配分
它表示 reasoning 在真正来源的 prompt 下的平均 token log-likelihood。
- matched 高:这条 reasoning 和原 prompt 很匹配;
- matched 低:这条 reasoning 在原 prompt 下也不太自然。
Marginal:混合 Prompt 下的平均匹配分
它表示这条 reasoning 放到整个 batch 的所有 prompts 里,平均来看有多合理。
Matched - Marginal:输入依赖性的核心
如果这个差很大,说明:
这条 reasoning 在自己的 prompt 下明显更合理,而不是对所有 prompt 都差不多合理。
这就是输入依赖强。
如果这个差接近 0,说明:
这条 reasoning 对自己的 prompt 没有特殊匹配性,放到别的 prompt 下也差不多。
这就是 template collapse。
两个主要 Proxy
Retrieval-Acc
对每条 reasoning,让模型在 batch 里的所有 prompts 中选一个最匹配的。如果选回了它真正来源的 prompt,就算正确。
- Acc 高:reasoning 能反推出原 prompt,输入依赖强;
- Acc 低:reasoning 像通用模板,分不清来自哪个 prompt。
MI-ZScore-EMA
先用 batch 的标准差做 z-score normalization,再用 EMA 平滑,避免训练曲线太抖。
例子:如何用 MI 检测 Template Collapse
假设 batch 里有 3 个 prompt:
现在 生成了一条 reasoning:
把它分别放到三个 prompt 下打分:
正常情况下, 应该最大,因为这条 reasoning 明显和 Countdown 的数字任务有关。
但如果 是:
I need to analyze the task carefully and choose the best next step.
那它放到 Sokoban、WebShop、Countdown 下都挺合理。于是三个分数差不多,Retrieval-Acc 就会低,MI proxy 也会低。
这就是 template collapse 的检测方式。
Why Does Template Collapse Happen?
RAGEN-2 认为,当策略梯度更新主要受输入无关的噪声而非任务区分性信号主导时,即 SNR 较低时,reasoning 会偏向那些在每个输入内部看似多样、却忽略跨输入差异的模板。
如果任务信号强,模型会学到:
这个输入下,哪种 reasoning/action 更好?
如果任务信号弱,模型就容易被一些通用的、输入无关的梯度牵着走,最终 reasoning 变成模板。
SNR 机制图在讲什么
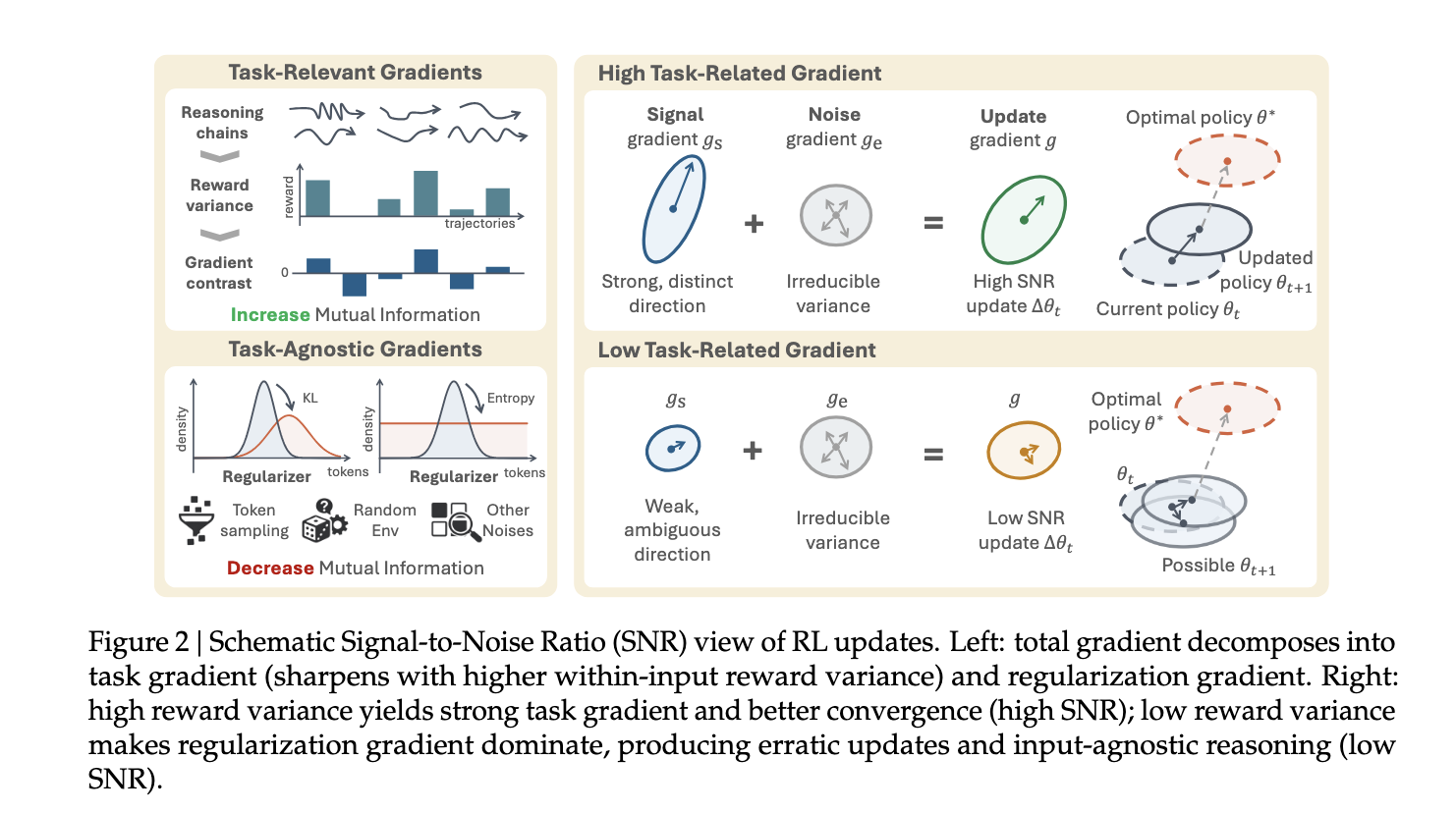
一次 RL 更新可以粗略看成两类力量相加:
其中:
- :task-related gradient signal,真正有用的任务信号;
- :noise / regularization / environment stochasticity,噪声或输入无关影响。
High SNR 情况下:
task gradient 很强,方向清晰,模型朝正确 policy 更新。
也就是说 reward 能清楚地区分好坏 trajectory,模型知道应该强化什么。
Low SNR 情况下:
task gradient 很弱,方向模糊,噪声和正则项影响更大,更新方向变得不可靠。
这时模型不是被具体任务差异驱动,而是被一些更通用的东西驱动,比如:
- KL regularizer:别偏离 reference model 太远;
- entropy regularizer:保持一定随机性;
- token sampling noise;
- environment randomness。
这些因素本身不关心输入内容,所以会倾向于削弱不同输入之间的 reasoning 差异。
作者如何证明这个机制
作者把训练 prompts 按照 within-input reward variance 从低到高分成 6 个桶:Q1 到 Q6。
然后分别测:
- reward variance;
- task gradient norm;
- regularization gradient norm。
实验发现:
- reward variance 越高,task gradient 越强;
- regularization gradient 基本是平的;
- 低 reward variance prompt 会让更新被输入无关项主导。
换句话说,无论 prompt 是高 reward variance 还是低 reward variance,KL / entropy 都会继续施加影响。
| Prompt 类型 | task gradient | regularization gradient | 谁更主导 |
|---|---|---|---|
| 高 reward variance | 强 | 差不多 | task signal 更明显 |
| 低 reward variance | 弱 | 差不多 | regularization 相对主导 |
所以低 reward variance prompt 不是“没影响”,而是可能产生坏影响:
它没有提供足够任务信号,但仍然让输入无关的 regularization 参与更新。
为什么 Reward Variance 控制 Task Gradient
对于同一个输入 ,采样 条 trajectory。每条 trajectory 的 advantage 是:
task gradient 可以写成:
如果同一个 prompt 下 reward variance 很低,那么:
所以:
于是 task gradient 自然会变弱。
SNR 中的噪声是什么
RAGEN-2 可以把总梯度拆成:
:真正有用的信号
这是最希望模型学到的部分。它来自同一个 prompt 下,不同 trajectory 的 meaningful reward differences。
比如 Sokoban 里:
- trajectory A 把箱子推到目标点,reward 高;
- trajectory B 把箱子推到死角,reward 低。
这种差异是有意义的。它告诉模型:A 的 reasoning/action 更好。
:任务采样噪声
这部分也来自 prompt 层面,但它不一定有意义。
例如:
- 环境随机性;
- rollout sampling randomness;
- stochastic transition;
- reward 本身有噪声。
在 FrozenLake 这种随机环境里,agent 可能做了正确动作,但环境随机滑到别处,导致 reward 差。这时候 reward variance 里混入了 noise。
这也是为什么 SNR-Aware Filtering 不是永远有效:如果环境随机性太高,reward variance 本身也会变成不可靠信号。
:输入无关的正则项
这部分来自:
- KL regularization;
- entropy regularization。
它是 chain-level 的,而且不直接依赖 reward 差异。
所以作者认为它是最容易导致 template collapse 的力量:
它不是针对“这个输入应该怎样 reasoning”来更新,而是对所有输入施加类似的约束。
当 task signal 强的时候,它只是稳定训练;当 task signal 弱的时候,它就可能主导更新,抹平 input dependence。
为什么低 RV 导致 MI 下降,但 Entropy 不一定下降
回到 template collapse 的两个指标:
低 reward variance 时,task gradient 弱。模型无法通过 reward 学到:对于不同输入,应该产生不同 reasoning。于是跨输入差异减小, 下降。
但是 entropy regularization 还可能继续鼓励输出多样性,所以同一个输入下仍然可能有多种说法, 不一定下降。
于是就出现了 RAGEN-2 想强调的“隐形 collapse”:
SNR-Aware Filtering
如果低 reward variance 会导致低 SNR,那么自然的解决方法是:
每轮训练时,计算每个 prompt 的 reward variance,只保留高 variance prompt 更新。
具体做法:
- 对每个 prompt 采样 条 trajectory;
- 计算这些 trajectory 的 episode return;
- 计算该 prompt 的 reward variance;
- 按 variance 排序;
- 保留高 variance 的 prompts;
- 只用这些 prompts 的 trajectories 做 policy update。
这类 prompt 更有训练价值,因为它们能告诉模型:同一个输入下,哪些 reasoning/action 比其他选择更好。
实验
Template Collapse 是否真的发生
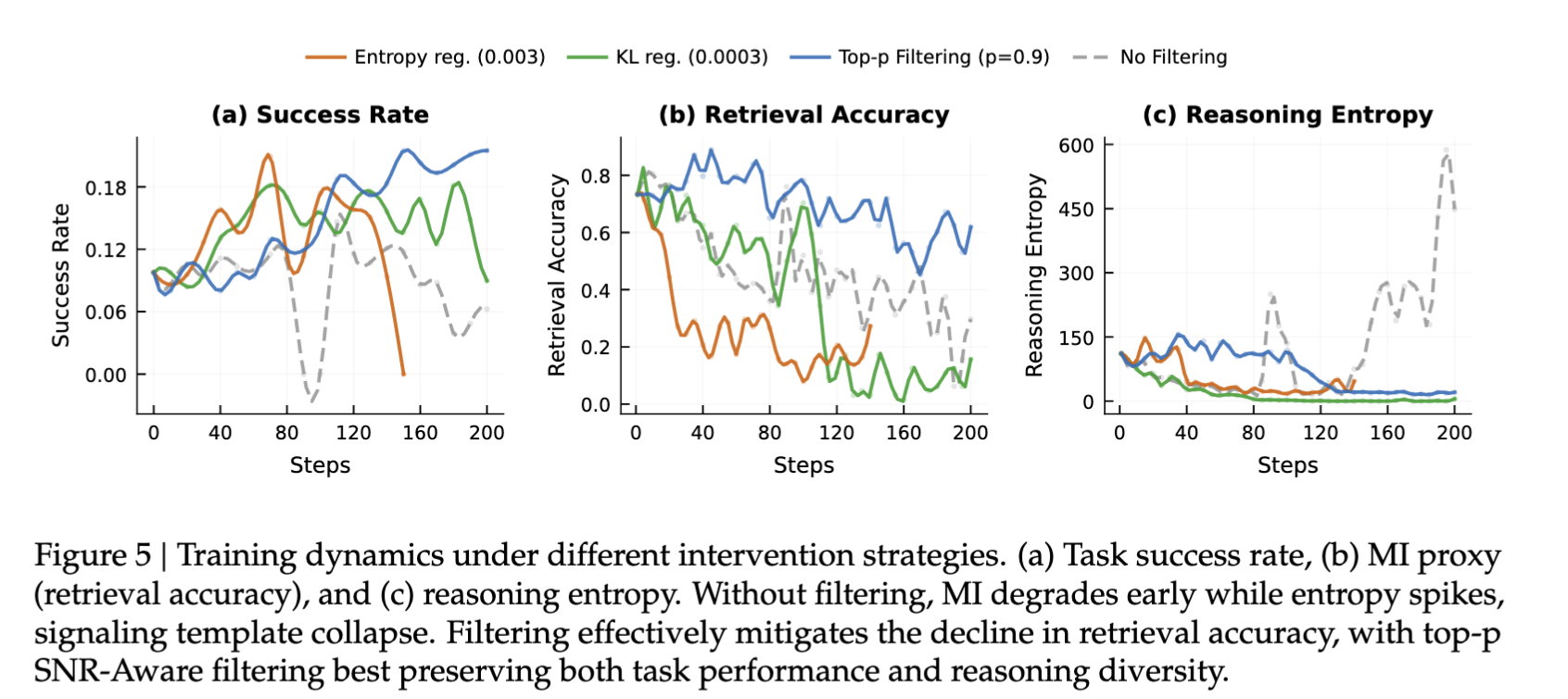
在 no filtering 的情况下,MI 很早就下降,但 entropy 仍然保持较高甚至上升。
这正是 template collapse 的特征:
也就是说,模型 reasoning 仍然“看起来多样”,但已经越来越不依赖输入。
行为层面的 Collapse 证据
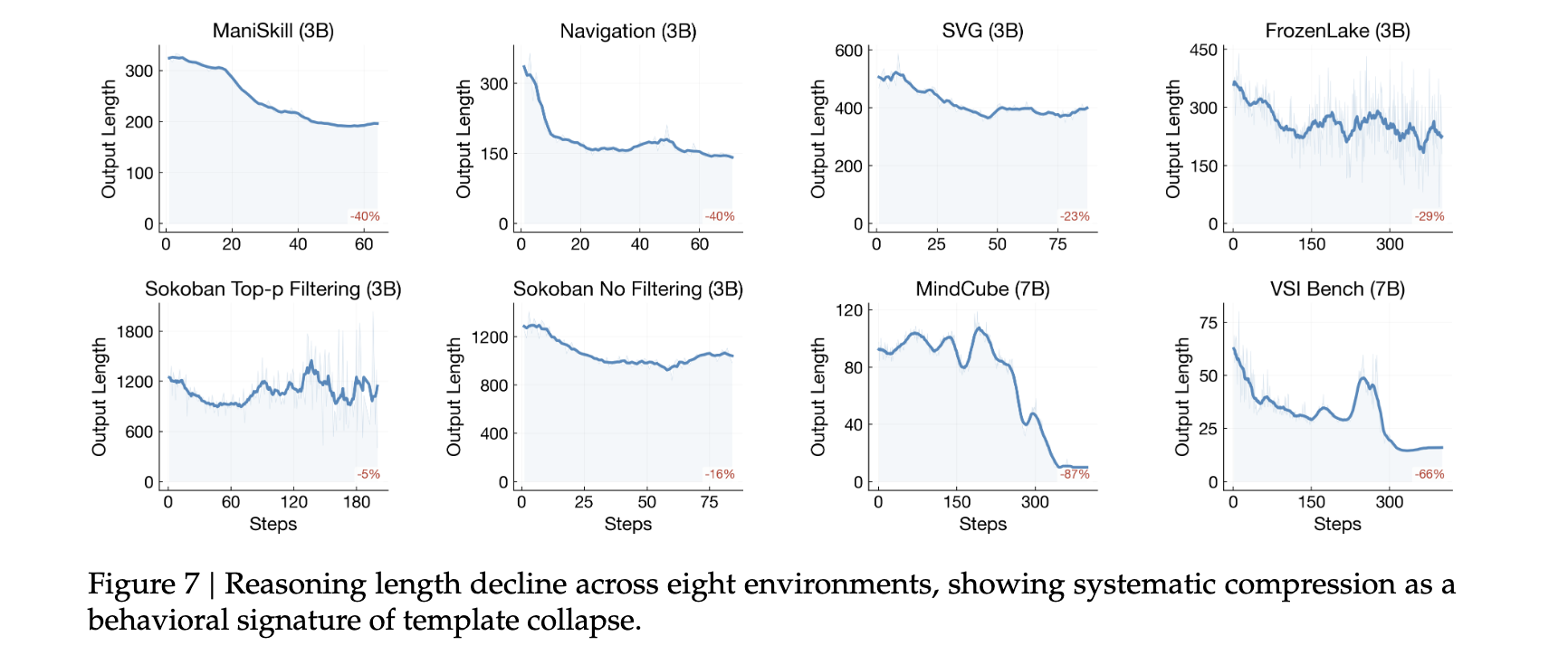
作者提到,在 8 个环境中,reasoning length 都呈下降趋势。
这说明随着 RL 训练推进,模型 reasoning 逐渐变短、变压缩、变模板化。它不一定完全不输出 reasoning,但会越来越倾向于复用短而安全的通用结构。
LL 思考:
这里为什么能得到长度下降就是模板化的结论?为什么不能是推理越来越正确,所以废话变少?
SNR-Aware Filtering 是否有效
作者比较三种策略:
- No Filtering:所有 prompt 都用于更新;
- Top-k Filtering:固定保留 reward variance 最高的 个 prompt;
- Top-p Filtering:按 reward variance mass 自适应保留 prompt。
结果是:
Top-p filtering 在多个环境中表现最好。
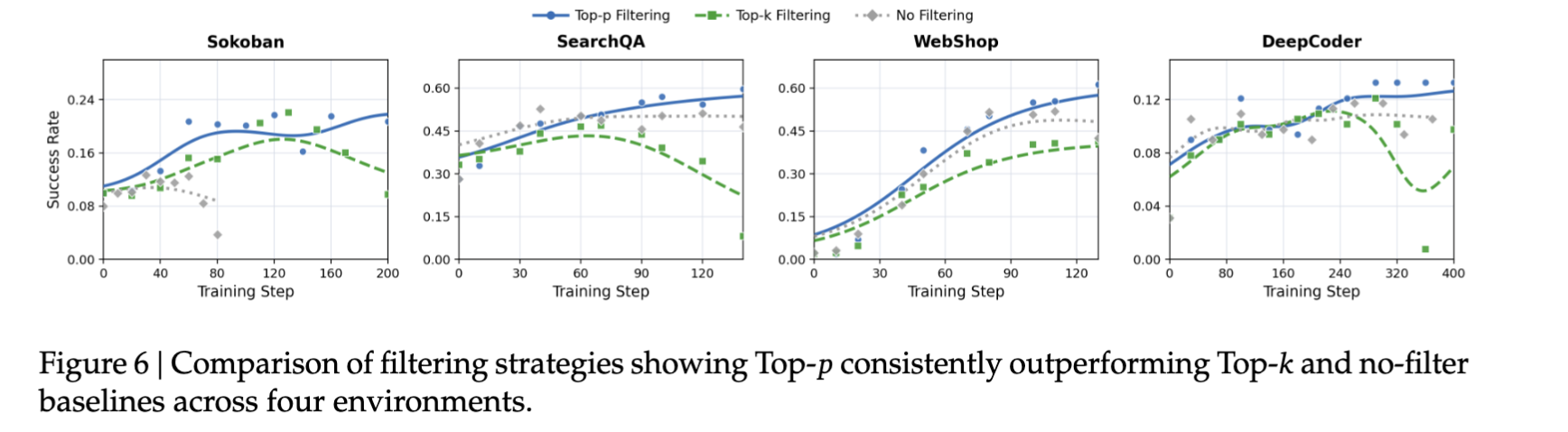
为什么 Top-p 比 Top-k 更好
Top-k 是固定保留数量。比如每轮固定保留 reward variance 最高的 4 个 prompt。
问题是:如果这一轮所有 prompt 的 reward variance 都很低,Top-k 还是会强行保留 4 个。这可能把低信号 prompt 也拿去更新。
Top-p 是按 variance mass 保留。如果少数 prompt 贡献了大部分 reward variance,它就只保留这些高信号 prompt;如果整批 prompt 都没什么信号,它保留数量会更少。
所以 Top-p 更自适应,也更符合 SNR 机制。
局限与思考
作者的 MI proxy 是:把某条 reasoning trace 放到 batch 里所有 prompts 下做 teacher-forced scoring,看它是否最匹配原 prompt。如果能匹配回去,说明 input dependence 高;如果匹配不回去,说明 reasoning 更模板化。
个人观点:这里可能存在隐患。MI proxy 测到的是 prompt 的表面可识别性,并不一定完全对应 reasoning 质量。
比如,如果 reasoning 只是在反复重复 prompt 中的某些细节,也可能带来高 Retrieval-Acc。相反,有些高质量 reasoning 可能在“匹配回原 prompt”这个角度上不明显,但仍然是有效推理,因而可能被低估。
因此,RAGEN-2 的 MI proxy 更适合作为 reasoning input dependence 的在线诊断指标,而不是 reasoning quality 的完整评价。