DeepSeek-R1: 只奖励结果,推理能力会自己长出来吗?
本文最后更新于:2026年6月22日 下午
DeepSeek-R1: 只奖励结果,推理能力会自己长出来吗?
Nature, 2025
论文信息
- 论文标题:DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
- 作者:Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi et al.
- 机构:DeepSeek-AI
- 发表信息:Nature 645, 633-638 (2025)
- 版本信息:Nature online published 于 2025-09-17;arXiv v1 提交于 2025-01-22
- DOI:10.1038/s41586-025-09422-z
- Nature
- arXiv:2501.12948
- Nature PDF
- arXiv PDF
- Models
TL;DR
DeepSeek-R1 的核心问题是:如果只奖励最终答案正确性,而不手把手教模型怎么写推理过程,LLM 能不能自己学出更强的 reasoning?
论文先训练了 DeepSeek-R1-Zero。它从 DeepSeek-V3-Base 出发,不经过 SFT,只用 GRPO 和 rule-based reward 在数学、代码、逻辑等答案可验证任务上做强化学习。结果表明,模型确实会自发出现更长的推理、反思、验证和重新规划等行为。
但 R1-Zero 也有明显问题:可读性差、语言混杂、输出格式不稳定。因此最终的 DeepSeek-R1 不是纯 RL 模型,而是一个多阶段系统:先用 cold-start SFT 给模型一个更可读的推理格式,再用 RL 强化推理能力,然后通过 rejection sampling 和第二次 SFT 扩展通用能力,最后再做一次面向 helpfulness / harmlessness / reasoning 的 RL。
一句话总结:
R1-Zero 证明了 RL 可以激发推理能力;DeepSeek-R1 则说明,真正可用的推理模型仍然需要在 RL、SFT、筛选数据和偏好对齐之间做工程平衡。
Overview
过去让大模型“会推理”,主要依赖三类方法:
Scaling
模型变大之后,会涌现出一些数学、逻辑和代码能力。但这条路需要大量计算资源,成本很高。
CoT Prompting
人类在 prompt 里告诉模型“一步一步想”,或者给它一些 few-shot 推理示例。这种方法有效,但本质上仍然依赖人类设计的推理轨迹。
SFT / Preference Data
用人工或模型生成的 CoT 数据做监督微调,再用偏好数据对齐输出风格。这能让模型更像人类推理,但也可能把模型限制在人类写出来的推理模式里。
DeepSeek-R1 的假设是:
人工定义的推理过程可能不是模型最适合的推理方式。对于数学、代码、逻辑这类答案可验证的任务,直接奖励最终结果,可能更能激发模型自己探索推理策略。
这也是论文最重要的思想:不教过程,只奖励结果。
DeepSeek-R1-Zero
DeepSeek-R1-Zero 可以写成:
1 | |
它是论文中最关键的验证实验。作者没有先准备人工 CoT 数据,也没有先做 instruction tuning,而是直接从 base model 开始强化学习。
训练模板
模型只收到一个非常简单的格式约束:
1 | |
也就是说,训练不会告诉模型“应该怎么推理”,只要求它把推理和答案分开放。
GRPO
DeepSeek-R1-Zero 使用的是 GRPO, Group Relative Policy Optimization。
相比 PPO,GRPO 不额外训练 value model,而是对同一个问题采样一组回答,用组内相对好坏估计 advantage。
如果对同一个 prompt 采样 个回答,奖励为 ,那么第 个回答的 advantage 可以理解为:
直觉上:
1 | |
GRPO 的好处是省掉了 value model,训练成本更低,也很适合答案可验证的 RLVR 场景。
Reward Design
R1-Zero 的奖励主要有两类。
Accuracy Reward
用于判断最终答案是否正确:
- 数学题:检查最终答案是否和标准答案一致;
- 代码题:运行测试用例;
- 逻辑题或选择题:检查选项或最终结论。
Format Reward
用于约束输出是否符合 <think> 和 <answer> 的格式。
作者刻意避免使用 neural reward model 来判断推理过程质量。原因很直接:reward model 本身可能被 policy model 钻空子。模型可能学会生成看起来像“高质量推理”的格式、语气和长度,但最终答案并不可靠。
因此,R1-Zero 的奖励设计很克制:
能用规则判定的,就尽量用规则判定;能奖励最终答案,就不要轻易奖励看起来漂亮的过程。
Reasoning 能力如何被激发
R1-Zero 最有意思的现象是:随着 RL 训练推进,模型的推理长度和求解能力一起提升,并且出现了一些类似反思的行为。
模型会开始:
- 尝试更多中间步骤;
- 检查自己的推导;
- 发现错误后回退;
- 在多种解法之间切换;
- 对复杂问题分解子目标。
论文中把这类现象称为 reasoning behavior 的 emergence。它说明,在答案可验证任务上,最终结果奖励不只是让模型记住答案,还可能推动模型形成更有效的搜索和验证策略。
但这并不意味着 R1-Zero 可以直接作为产品模型使用。
R1-Zero 的问题
R1-Zero 证明了 RL 可以激发 reasoning,但它的问题也很明显。
可读性差
因为没有经过 cold-start SFT,模型的推理过程经常很长、很乱,不一定符合人类阅读习惯。
语言混杂
中英文混用很常见。比如用户用中文提问,模型的 reasoning 里可能突然混入大量英文。
格式不稳定
模型虽然有 format reward,但在长推理中仍然可能出现格式漂移。
通用能力不足
R1-Zero 主要面向可验证推理任务,不能自然覆盖写作、对话、开放问答、安全对齐等通用场景。
因此,DeepSeek-R1 的完整训练流程不是“纯 RL 一步到位”,而是把 R1-Zero 的推理能力和 SFT / preference alignment 结合起来。
DeepSeek-R1
DeepSeek-R1 可以理解为:
1 | |
R1-Zero 是一个证明 RL 能激发推理的实验模型;DeepSeek-R1 则是一个面向实际使用的综合模型。
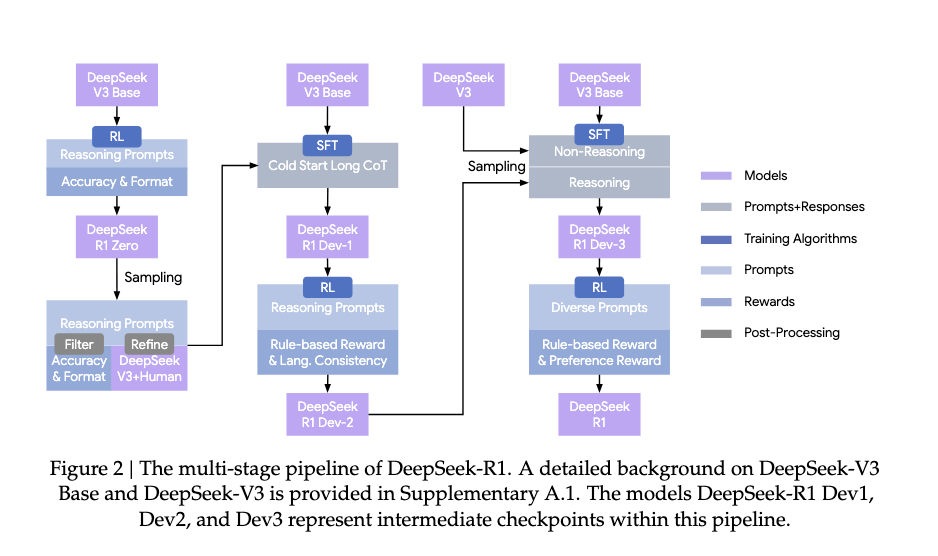
Stage 1: Cold-Start Long CoT SFT
第一阶段先收集几千条 cold-start long CoT 数据。
数据来源主要有两类:
- 从 DeepSeek-R1-Zero 的输出中筛选较好的推理轨迹,再人工整理成更可读的格式;
- 用 DeepSeek-V3 生成或扩写更多 long CoT 数据。
这一阶段的目标不是把模型训练到最强,而是先解决 R1-Zero 的可读性和格式问题。经过 cold-start SFT 后,模型学会了更稳定地组织推理过程和最终答案。
Stage 2: Reasoning-Oriented RL
经过 cold-start SFT 后,作者继续做第一轮 RL。这一轮仍然主要面向 reasoning prompts。
奖励包括:
1 | |
rule-based reward 和 R1-Zero 类似:
- 数学看答案;
- 代码跑测试;
- 逻辑任务看最终结论。
新增的 language consistency reward 用来缓解语言混杂问题。论文给出的形式是:
意思是,如果题目是中文,就希望推理过程主要是中文;如果题目是英文,就希望推理过程主要是英文。
这个奖励可能轻微损害 benchmark performance,但可以显著改善输出体验。这里也能看出 DeepSeek-R1 和 R1-Zero 的区别:前者不仅追求能做对题,还追求回答对用户可读、稳定、可控。
Stage 3: Rejection Sampling + 第二次 SFT
第一轮 RL 后,模型已经具备更强的 reasoning 能力。接下来作者用它生成大量候选回答,再进行 rejection sampling。
rejection sampling 的逻辑很简单:
1 | |
这些筛选出来的数据会用于第二次 SFT。
这一阶段的数据不只包含 reasoning 数据,还包含 non-reasoning 数据:
- 写作;
- 角色扮演;
- 通用问答;
- 软件工程;
- instruction following;
- 由 DeepSeek-V3 生成的部分数据。
所以第二次 SFT 的作用是:在保留 reasoning 能力的同时,把模型拉回一个更通用、更好用的聊天模型。
Stage 4: Second RL Stage
第二次 SFT 后,作者再做一轮 RL,得到最终的 DeepSeek-R1。
这一轮 RL 不只优化 reasoning,还加入 general prompts 和 preference reward。可以粗略理解为:
其中:
也就是说:
- 对数学、代码、逻辑:继续用 rule-based reward;
- 对通用任务:用 reward model 判断 helpfulness 和 harmlessness;
- 对语言:继续加入 language consistency reward。
最终目标是让模型同时具备三件事:
1 | |
Distillation
论文另一个重要部分是 distillation。作者发现,可以用 DeepSeek-R1 生成的 reasoning 数据去蒸馏更小的开源模型。
这说明 R1 的价值不只在于训练出一个大模型,也在于提供高质量 reasoning traces,让较小模型通过 SFT 学到一部分推理模式。
这里有一个很重要的启发:
RL 负责探索出更强的推理策略,distillation 负责把这些策略压缩到更便宜、更容易部署的模型里。
这也是后续很多 reasoning model 的常见路线:先用强模型或 RL 模型产生高质量推理数据,再把能力蒸馏给小模型。
为什么 DeepSeek-R1 重要
DeepSeek-R1 的意义不只是 benchmark 分数高,而是它把 reasoning model 的训练路线讲得很清楚。
1. RLVR 是可行的
在数学、代码、逻辑等任务中,只要最终答案可以验证,就可以构造比较可靠的 rule-based reward。
这类任务不需要人类逐步标注推理过程,也不一定需要 reward model 判断“推理写得好不好”。模型可以通过反复采样、比较和更新,自己找到更有效的推理策略。
2. 过程监督不是唯一道路
过去很多工作默认推理能力需要人类提供 CoT 数据。但 R1-Zero 表明,至少在可验证任务上,outcome reward 也能激发复杂推理。
这并不是说过程监督没用,而是说明:
人类 CoT 不是推理能力的唯一来源;环境反馈和最终答案奖励也可以成为推理能力的来源。
3. 纯 RL 不等于最终产品
R1-Zero 很强,但不可读、不稳定、不够通用。DeepSeek-R1 的完整 pipeline 说明,实际产品模型仍然需要 SFT、rejection sampling、preference alignment 和 safety alignment。
所以更准确的结论不是“RL 替代 SFT”,而是:
RL 用来探索能力边界,SFT 和 alignment 用来把能力整理成用户可用的形式。
Limitation
论文也明确提到 DeepSeek-R1 仍然有一些不足。
结构化输出和工具使用不够好
对 JSON、函数调用、工具链协作等任务,R1 并不一定比专门训练过的模型更稳定。
Token efficiency 问题
R1 容易 overthinking。简单问题也可能生成较长推理,浪费 token。
语言混杂仍然存在
language consistency reward 能缓解问题,但不能完全解决多语言场景中的混杂。
Prompting sensitivity
Few-shot prompting 可能降低 DeepSeek-R1 的性能。对 reasoning model 来说,过多示例有时会干扰模型自己形成的推理策略。
软件工程任务提升有限
代码竞赛和可测试代码任务适合 rule-based reward,但真实软件工程涉及需求理解、仓库上下文、长期维护和工具使用,奖励更难定义。
Reward hacking 风险
对开放任务很难构造可靠 reward。如果使用 neural reward model,policy model 可能逐渐学会迎合 reward model,而不是真的变强。
我的理解
DeepSeek-R1 最值得关注的地方,是它把“推理”从一种人工书写的文本格式,重新放回到“为了拿到正确答案而进行的搜索过程”里。
过去我们常常把 CoT 当成能力本身:模型写了很多步骤,就像是在推理。但 R1-Zero 说明,更关键的是训练信号是否能区分好坏。如果 reward 足够可靠,模型可能自己找到人类没有显式设计的推理路径。
不过,这条路线也有边界。RLVR 最适合答案可验证的任务。一旦任务变成开放写作、真实 agent 交互、复杂软件工程或多轮工具使用,最终 reward 就会变得稀疏、延迟且难以判定。这也是为什么后续 Agentic RL 的工作会继续讨论 rollout allocation、credit assignment、template collapse 和 reward hacking。
所以 DeepSeek-R1 更像是一个起点:
1 | |
这也是 Agentic RL 继续往前走的核心问题。