MeRF: 训练时告诉模型评分规则会怎样?
本文最后更新于:2026年6月29日 下午
MeRF: Motivation-enhanced Reinforcement Finetuning
ICLR 2026
论文信息
- 论文标题:A Simple “Motivation” Can Enhance Reinforcement Finetuning of Large Reasoning Models
- 作者:Junjie Zhang, Guozheng Ma, Shunyu Liu, Haoyu Wang, Jiaxing Huang, Ting-En Lin, Fei Huang, Yongbin Li, Dacheng Tao
- 机构:Nanyang Technological University; Tongyi Lab, Alibaba Group
- 发表信息:International Conference on Learning Representations (ICLR), 2026
- 版本信息:arXiv v1 提交于 2025-06-23,v3 修订于 2026-03-09
- 论文页数:21 pages
- 主题分类:cs.CL
- DOI:10.48550/arXiv.2506.18485
- arXiv:2506.18485
TL;DR
RLVR 训练时,直接在 prompt 中告诉模型评分规则,也就是把 reward function 的自然语言描述塞进 prompt。
Abstract + Introduction
当前 RLVR 的训练过程本质是模型在试错,效率不高。既然 RLVR 的 reward 是可验证的,通常也可以用自然语言描述,那为什么不在训练时直接告诉模型评分规则?作者把这种“让模型知道 reward function”的做法叫作 motivation。本文提出 MeRF: Motivation-enhanced Reinforcement Finetuning,把 reward specification 直接注入 prompt,作为 in-context motivation。
LL 说:
这个方法的原理很像高中做完数学大题和标准的参考答案一步一步订正打分。订正答案要参考高考评分标准,知道如何做才能得分很关键。
贡献
第一,提出 MeRF,通过 in-context motivation 让模型知道 optimization objective,从而提升 RLVR 效率。
第二,在多个 reasoning benchmark 上实验,包括 K&K Logic Puzzles、AIME24&25、AMC23、MATH500 和 CountDown,证明 MeRF 超过 RLVR baseline。
第三,做机制分析,尤其关注 in-context motivation 与真实 reward function 的一致性。这点很重要,因为如果 prompt 里写的 motivation 和外部 reward 不一致,模型到底听谁的?
读完 Intro,直观感受是这方法太简单。打开 OpenReview,还真有人给了个 2 分。
AC 也提到这个问题,但是持积极观点,认为 MeRF 的简洁性恰恰是它吸引人和实用的地方。
Method
动机: reward function 在训练系统里很清楚,但对模型来说是“隐藏规则”。模型只能通过“这次得几分”慢慢反推规则。
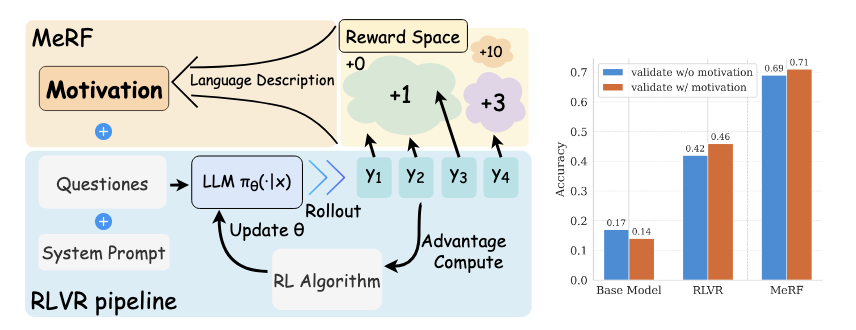
普通 RLVR 流程是:
Question + System Prompt → LLM 生成多个 rollout:y1, y2, y3, y4 → reward function 给分,比如 +0、+1、+3、+10 → 计算 advantage → RL algorithm 更新参数 θ
MeRF 在这个流程上加了一个东西:
Motivation = reward space 的 language description
也就是把奖励函数的自然语言描述放进 prompt。
这张图对比了三种模型在测试时加不加 motivation 的性能差别。作者认为,MeRF 的主要收益来自训练过程中 motivation 改善了 RL 学习,而不是推理时临时多加一段提示词。
Experiment
实验目标:比较普通 RLVR 和 MeRF,看训练时加入 motivation 是否能提升 reasoning model 的强化微调效果。
基座模型:Qwen2.5 系列 + DeepSeek-R1-Distill 系列
实验任务:
第一类是 K&K Logic Puzzles,也就是 Knights and Knaves 逻辑题。这个任务里每个人要么是 knight,要么是 knave;knight 永远说真话,knave 永远说假话。模型要根据每个人的陈述判断所有人的身份。
第二类是 数学 benchmark,包括:
- AIME24
- AIME25
- AMC23
- MATH500
第三类是 CountDown,一个数字游戏任务。模型需要使用给定数字和加减乘除得到目标数;每个数字只能用一次,实验中给定数字数量是 3 或 4 个。
它们的共同特点是:reward function 都比较容易写成自然语言规则。这正好适合 MeRF。
实验结果显示:MeRF 在 K&K 上提升非常明显,在数学任务上也有稳定但较小的提升。最重要的是,K&K 的主结果是在测试时不加 motivation 的情况下得到的,说明 MeRF 的收益主要来自训练过程,而不是测试 prompt trick。
机理分析
Q1:MeRF 的提升是不是来自 inference-time motivation?
作者第一个要排除的解释是:
MeRF 会不会只是因为测试时 prompt 里多了评分规则?
他们用 Figure 2 右图和 Figure 7 来回答。结论是:不是主要原因。
论文说,对于 RLVR 和 MeRF model,测试时加入 motivation 只带来小幅提升:RLVR 大约 +4%,MeRF 大约 +2%。但 MeRF 相比 RLVR 的提升,在不加 motivation 测试和加 motivation 测试时分别大约是 +27% 和 +25%。所以作者认为,MeRF 的主要收益来自训练过程,而不是推理时多了一段提示词。
Q2:如果不是 inference,那 motivation 到底怎么帮 RL?
作者给出的机制解释是:
motivation 改善了训练中的 exploration,使模型更容易采样到正确答案;然后 RL 会放大这个初始优势。
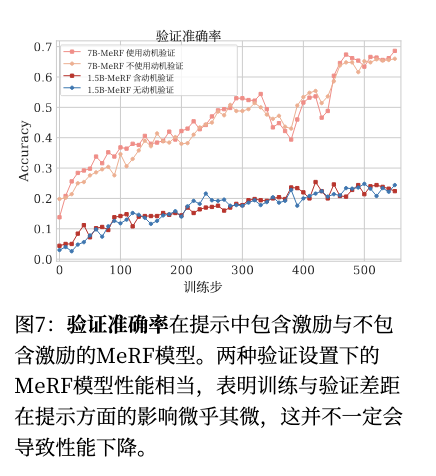
Q3:训练时有 motivation,测试时没有,会不会有 gap?
MeRF 训练时 prompt 里有 scoring rules,但 Table 1 的主要测试结果是 without motivation。这就存在 train-test prompt gap:
训练时:问题 + motivation 测试时:问题,不给 motivation
这会不会导致模型依赖 motivation,一旦测试拿掉就掉点?
作者用 Figure 7 回答。他们比较了 Qwen2.5-7B-Instruct 和 DeepSeek-R1-Distill-Qwen-1.5B 两个 MeRF 模型,在测试时 w/ motivation 和 w/o motivation 的表现。结果是两种测试设置表现接近,说明 train-validation gap 的影响可以忽略;作者认为模型能够从带 motivation 的训练泛化到不带 motivation 的验证。
Q4:motivation 不完整或错误会怎样?
作者比较了三种 motivation:
Ground-Truth Motivation
完整、准确地描述真实 reward function,包括 correctness score 和 format score。
Suboptimal Motivation
只描述 correctness score,不描述完整 reward。也就是信息不完整。
Adverse Motivation
故意误导模型。它描述完整 reward structure,但把分数反过来:正确答案反而给负分,错误或不可解析反而给正分,格式正确也给负分。Figure 8 右侧展示了这些 motivation 的具体片段。
实验结果是:
Ground-truth motivation 最好; Suboptimal motivation 也比 RLVR 好; Adverse motivation 一开始会误导模型,训练不稳定,但后面模型似乎能适应,最终仍有一定表现。
论文总结说,MeRF 受益于 motivation 和真实 reward function 的一致性;一致性越好,表现越好。同时,模型在 RL 过程中也有能力适应 adverse motivation,可能学会 discount 掉误导性 motivation。
OpenReview 总结
得分:2,6,6,4
审稿人普遍认可 MeRF 简单有效,但主要质疑它是否只是 prompt engineering,以及它的机制和泛化边界。最终 AC 认为,尽管方法依赖可描述 reward,泛化边界有限,但在 RLVR 场景下它足够简单、有效、实用,因此接收为 poster。